|
6 тур - з 11.12 по 17.12.2017
точка входу для відправлення розв’язків
http://134.249.159.199/cgi-bin/new-client?contest_id=48
(скачати)
Задача A-Послідовність
|
Ім’я вхідного файлу:
|
input.txt
|
|
Ім’я вихідного файлу:
|
output.txt
|
|
Ліміт часу:
|
1 с
|
|
|
Служба безпеки країни Унляндія отримала цікавий сигнал із космічного простору, який можна представити у вигляді послідовності із 0 та 1. Перед працівниками цієї служби відразу постало питання: а чи не можна якимось чином декодувати це повідомлення. Перед декодуванням було вирішено проаналізувати отриману послідовність. Оцінка полягала в тому, щоб у вказаній послідовності із 0 та 1 знайти такі підпослідовності, котрі повторюються найчастіше.
Обмеження:
а) кількість символів у підпослідовності повинна буди в межах від А до В включно.
б) шуканих послідовностей повинно бути не більше N.
Формат вхідних даних
Вхідний файл містить Числа А, В, N, кожне із яких записане в новому рядку. Четвертий рядок містить саме повідомлення, запис якого закінчується цифрою 2. Розмір вхідного файлу не більше 2 Мб.
1≤A≤12, 1≤B≤12, 1≤N≤20
Формат результату
Вихідний файл містить не більше N рядків, у кожному з яких записано через пропуск такі дані:
1. Кількість входжень знайденої підпослідовності (підпослідовностей, якщо декілька різних зустрічаються однакову кількість разів).
2. Сама послідовність (підпослідовності записані через пропуск, без дублювань).
Сортування:
* по рядках першими вказати підпослідовності, котрі трапляються найчастіше і далі по спаданню.
* Якщо знайдено декілька підпослідовностей, в яких однакова кількість входжень, то першими вказати ті, в яких більша кількість символів. Якщо кількість символів однакова, то першими вказати ті, які зустрічаються раніше при читанні повідомлення зліва направо.
Приклад
|
input.txt
|
output.txt
|
|
4
5
4
11111111111111011100111111111111111112
|
25 1111
23 11111
2 1110 0111
1 11110 11101 11100 11011 11001 10111 10011 01111 01110 00111 1101 1100 1011 1001 0011
|
Задача B-Зображення
|
Ім’я вхідного файлу:
|
input.txt
|
|
Ім’я вихідного файлу:
|
output.txt
|
|
Ліміт часу:
|
1 с
|
|
Ім’я вхідного файлу:
|
input.txt
|
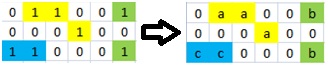
Бітове зображення розміром N x M задається сукупністю із 1 та 0, розміщених у відповідних клітинках. Суміжними називаються клітинки, що містять спільну «сторону» або «кут». Фрагментом називається сукупність всіх суміжних клітинок із одиничками на фоні нулів. Подібними називаються фрагменти, у яких рівна кількість 1 та однакове їх відносне розміщення (подібні також є фрагменти, котрі повернуті один відносно одного на кут кратний 90 градусів). У заданому таким чином зображенні потрібно знайти та виділити всі різні фрагменти. Під виділенням розуміється заміна всіх 1 в певному різновиді фрагментів на одну із латинських літер [a-z].
Для виділення подібних фрагментів потрібно використати одну із букв латинського алфавіту [a-z]. Для подібних фрагментів – однакова буква. Букви використовуються в алфавітному порядку. Призначення певної букви для фрагменту потрібно робити у порядку знаходження нових, переглядаючи зображення зліва направо та по рядках вниз (див. приклад).
Зображення розміром 6х3
Обмеження:
0 ≤ Ширина зображення ≤ 100
0 ≤ Висота зображення ≤ 100
0 ≤ Всього фрагментів ≤ 500
0 ≤ Різних фрагментів ≤ 26 [a-z]
У кожному із фрагментів не більше 160 одиничок.
Формат вхідних даних
Перші два рядки вхідного файлу містять числа N та M (відповідно ширина та висота зображення). Далі йдуть M рядків по N символів у кожному (1 або 0).
Формат результату
Вихідний файл повинен містити M рядків по N символів у кожному, що відповідають вихідному зображенню.
Приклад
|
input.txt
|
output.txt
|
|
6
3
011001
000100
110001
|
0aa00b
000a00
сс000b
|
|


