Поиск
Цель: поиск в массиве, поиск по дереву.
Одной из нескольких наиболее фундаментальных
операций, присущей огромному количеству
вычислительных задач, является поиск.
Поиск - нахождение какой-либо конкретной
информации в большом объеме ранее собранных
данных.
Данные делятся на записи, и каждая запись имеет
хотя бы один ключ. Ключ используется для того,
чтобы отличить одну запись от другой.
Целью поиска является нахождение всех записей
подходящих к заданному ключу поиска.
Вначале рассмотрим поиск с позиций
пользователя.
Кроме поиска совпадению аргумента поиска с
ключом записи, существует поиск по близости
аргумента и ключа и поиск по интервалу,
означающий попадание ключа в заданный двумя
аргументами (границами) интервал. В последнем
случае результат - множество записей, хотя бы и
пустое. При поиске по совпадению - также. Те же
принципы (условия) поиска применимы и к
преобразованным ключам - значениям некоторой
функции содержания записи.
Указанные выше условия поиска будем считать
элементарными.
Логически сложные условия поиска могут быть
конъюнктивными (обязательно выполнение в
искомых записях всех заданных элементарны
условий), дизъюнктивными (достаточно выполнения
одного из них) смешанной природы.
Рассмотренный выше поиск назовем ординарным,
ибо возможно толкование тех же условий на более
сложном, так называемом семантическом плане.
Пример: найти, среди многих, реферат статьи,
наиболее близкий к указанной теме.
Итак, возможна следующая классификация случаев
поиска:
Для поиска по совпадению можно было бы
отделить случай поиска единственной записи от
случая поиска многих записей.
Эту классификацию не следует путать с
классификацией средств поиска. Любой случай
может быть реализован как простой перебор
записей (медленный поиск) и как бинарный (быстрый)
поиск.
Для удобства программирования будем искать в
массиве запись, ближайшую снизу к левой границе и
не равную ей, и запись, ближайшую сверху к правой
границе и не равную ей. Эти записи в ответ не
входят. Если найденные записи являются
соседними, результатом оказывается пустое
множество записей.
Рассмотрим простой перебор записей. Его можно
реализовать с помощью следующего алгоритма.
function search(x: integer): integer;
var
i: integer;
begin
for i:=1 to n do
begin
if x = a[i] then
begin
search := i;
exit;
end;
end;
search:=0;
end;
Реализуем более сложный алгоритм поиска. Этот
алгоритм называется бинарный поиск(дихотомия).
Смысл этого алгоритма в отсортированном
массиве ищем середину, если искомый элемент
меньше серединного элемента, то ищем в левой
части, а если больше, то в правой. У найденного
интервала снова ищем середину и опять сравниваем
искомый элемент и т.д.
Type fun= function (j:word):Boolean;
Function fa(j:word):Boolean; far; Begin fa:= A[j] < x1 End;
Function fb(j:word):Boolean; far; Begin fb:= A[j] > x2 End;
Procedure Search(f1,f2:fun; L:integer; var m,k,usp:word);
Var i,j,kk:word;
Begin usp:=1; i:=m+1; kk:=k;
If L<>1 Then
Begin {Цикл бинарного поиска по функции f2: }
Repeat j:=(i+kk) div 2; If f2(j) Then kk:=j Else i:=j+1
Until i=kk; If i=m+1 Then usp:=0
Else If (L > 1) And f1(i-1) Then usp:=0
End; {i - номер найденной записи с ближайшим к
аргументу
большим (строго) ключом} If usp = 0 Then Exit;
If (L > 2) Or (L = 1) Then
Begin i:=kk-1; {Отыскивается запись, ограничивающая
снизу
группу искомых записей; цикл бинарного поиска по
функции f1:}
Repeat j:=(m+i+1) div 2; If f1(j) Then m:=j Else i:=j-1
Until m=i;
If L=1 Then Begin If m=k-1 Then usp:=0; i:= m+1 End
End
Else If (L=-1) Or Not f1(i-1) Then i:=i-1;
m:=i; k:=kk
End;
Параметром L мы задаем случай поиска: L = -1 (L = 1)
при поиске по близости снизу (сверху); L = 2 при
поиске по совпадению (одна запись); L = 3 при поиске
по совпадению (все записи) или по интервалу.
При L = 3 и usp = 1 (поиск успешен) найденные номера m
(меньший), k (больший) обозначают позиции,
непосредственно примыкающие к позициям группы
искомых записей, а в остальных случаях, когда usp = 1
("успех"), номером найденной записи является
m.
Аргумент поиска явно не показан, а скрыт в
записываемых пользователем логических функциях
f1, f2 с единственным параметром - номером j записи.
В fl (f2) записывается, что f1 (f2) истинна, когда ключ
записи меньше (больше) аргумента.
Параметры m, k - это не только результирующие
номера записей, но и (в момент обращения) внешние
границы исходной области поиска.
Для увеличения эффективности поиска в
отсортированном файле существует другой метод,
но он приводит к увеличению требуемого
пространства. Этот метод называется индексно -
последовательным методом поиска.
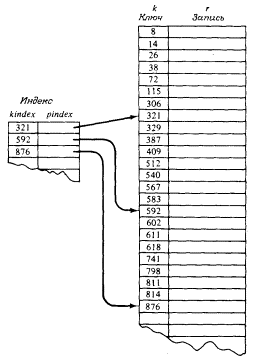
В дополнение к отсортированному файлу
заводится некоторая вспомогательная таблица,
называемая индексом. Каждый элемент индекса
состоит из ключа kindex и указателя на запись в
файле, соответствующую этому ключу kindex. Элементы
в индексе, так же как и элементы в файле, должны
быть отсортированы по этому ключу.
Если индекс имеет размер, составляющий одну
восьмую от размера файла, то каждая восьмая
запись в файле представлена первоначально в
индексе. Это показано на рисунке.
Поиск в Бинарном Дереве
Поиск в бинарном дереве является простым и
эффективным методом, который считается одним из
наиболее фундаментальных в компьютерной науке.
Он чрезвычайно легок в использовании, но на самом
деле он довольно широко используется во многих
ситуациях.
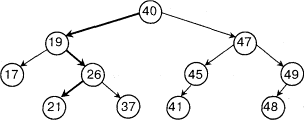
Рассмотрим следующее БДУ
Поиск по совпадению является самым
легким идем влево, если искомая запись меньше
ключа в узле и вправо, если больше либо равна.
Больший интерес вызывают случаи, когда идет
поиск по близости и поиск по интервалу.
Рассмотрим поиск по близости. При обходе дерева
указатели на узлы этого дерева по пути поиска
будем заносить в стек. При аргументе поиска 20 мы
останавливаемся на 21 и прекращаем поиск. Затем
смотрим на вершину стека и там находится
ближайшее число к 20.
При поиске по интервалу находим левую границу
или максимально к ней приближенную, а затем
просматриваем стек в обратном порядке(или если
нужно дерево) ищем правую границу, т.е. ищем все
узлы, которые больше либо равны левой границе, но
меньше правой.
Параметры сог - ссылка на корень БДУ, arl, ar2 -
аргументы поиска (значение аг2 задают лишь для
поиска по интервалу как правую его границу, но
параметр этот записывают всегда), L - вариант
поиска (при поиске по интервалу L=4), рр - признак
успешности
Procedure Obrab(ss:pt); {Obrab -
процедура-"заглушка", }
Begin Write(ss^.kl:5) End; {имитирующая обработку узлов}
Procedure Poisk(cor:pt; ar1,ar2:tipkl; l:integer; var pp:pt);
Label 1,2; {sl - поле ссылки на узел БДУ, ssl - связь в
стеке}
Type pnt=^z; z=Record sl:pt; ssl:pnt End;
Var rr,ss,tt: pt; q,t: pnt;
Procedure StekIn; {Блок включения в стек t ссылки на узел
БДУ}
Begin New(q); q^.sl:= ss; q^.ssl:=t; t:=q End;
Begin pp:= Nil; rr:= Nil; t:= Nil; tt:= cor;
If l = 3 Then ar2:=ar1;
While tt <> Nil do {Цикл прохождения трассы поиска}
Begin ss:= tt;
If ss^.kl = ar1 Then {Усечение трассы при совпадении
ключа}
Begin pp:= ss; StekIn; Goto 1 End;
If ss^.kl > ar1 Then Begin tt:= tt^.lson; StekIn End
Else Begin tt:= tt^.rson; rr:= ss End
End;
If (l <> 2) And (t <> Nil) Then pp:= t^.sl;
If l=-1 Then pp:= rr;
1:If pp <> Nil Then If l < 3 Then Obrab(pp)
Else If t^.sl^.kl > ar2 Then pp:= Nil
Else {2-й ЭТАП РАБОТЫ - для l=3,4:}
While t <> Nil do {Цикл частичного обхода БДУ слева}
Begin q:= t; ss:=t^.sl; t:= t^.ssl; Dispose(q);
If ss^.kl > ar2 Then Goto 2;{Возможное завершение обхода}
Obrab(ss); ss:= ss^.rson;
While ss <> Nil do
Begin While ss^.lson <> Nil do {Проход влево "до упора"}
Begin StekIn; ss:= ss^.lson End;
If ss^.kl > ar2 Then Goto 2;{Возможное завершение обхода}
Obrab(ss); ss:= ss^.rson
End
End; {Конец цикла частичного обхода БДУ слева}
2:While t <> Nil do Begin q:=t; t:=t^.ssl; Dispose(q) End
End{блока поиска в БДУ};
Бинарное дерево является частным случаем
B-дерева.
В-деревом порядка m такое дерево определяется
как некоторое общее дерево, которое
удовлетворяет следующим условиям:
- Каждый узел содержит максимум m-1 ключей.
- Каждый узел, за исключением корневого, содержит
по крайней мере int((m-l)/2) ключей.
- Корень имеет по крайней мере двух сыновей, если
только он не является некоторым листом.
- Все листья находятся на одном и том же уровне.
- Узел с n ключами, который не является листом,
имеет п+1 сыновей.
На рис. показано некоторое В-дерево
порядка 5. Отметим, что каждый узел может быть
.представлен как некоторый упорядоченный
набор(p1, k1, p2, k2, ..., kn-1, рn) где pi является указателем
(возможно, пустым, если данный узел является
листом), а ki является некоторым ключом.
Все ключи в узле, на которые указывает pi,
находятся между ki-1 и ki, а внутри каждого узла
выполняется неравенство k1<k2<.. .<kn-1.
Дерево 2-3-4 тоже является частным случаем
B-дерева.
B-деревья очень эффективны при поиске.
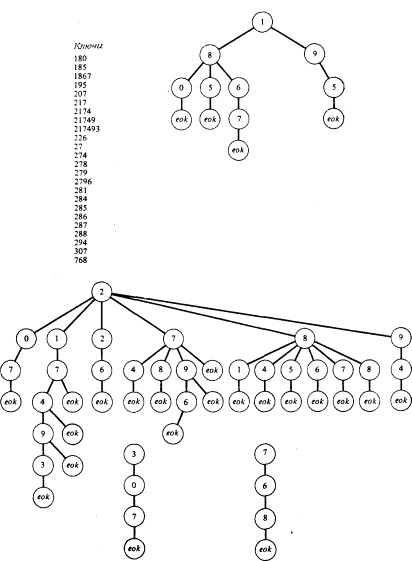
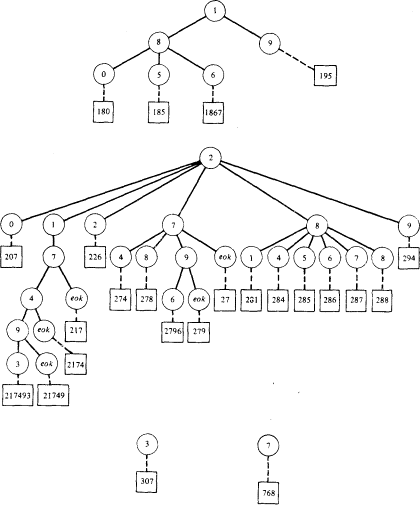
Деревья цифрового поиска
Другой метод использования деревьев для
ускорения поиска состоит в формировании
некоторого общего дерева, основанного на
символах, из которых состоят ключи. Например,
если ключи являются числовыми, то каждая позиция
цифры определяет одного из 10 возможных сыновей
заданного узла.
Каждый узел, являющийся листом дерева,
содержит специальный символ eok, который
представляет конец некоторого ключа. Такой узел,
являющийся листом, должен также содержать
некоторый указатель на запись, которая
запоминается.
Однако данное дерево можно сделать даже еще
меньше, исключив те узлы, из которых можно
достичь только одиночных листьев.
Штриховая линия используется для
представления указателя от узла дерева на ключ.
Итак, на сегодняшнем занятии мы рассмотрели
основные алгоритмы поиска. |