В ходе этого урока вы узнаете о том, как можно повысить скорость рабогы операторов SQL с помощью создания и использования индексов таблиц.
Сначала будет рассмотрено использование команды CREATE INDEX, с помощью которой создаются индексы таблиц, а затем использование самих индексов.
Основными на этом уроке будут следующие темы.
• Создание индексов
• Принципы работы индексов
• Различные типы индексов
• Когда следует использовать индексы?
• Когда не следует использовать индексы?
Упрощенно говоря, индекс — это указатель на данные в таблице. Индекс в базе данных подобен предметному указателю в книге. Например, если вы хотите просмотреть все страницы книги, на которых идет обсуждение интересующего вас предмета, вы сначала обращаетесь к предметному указателю, где все предметы перечислены в алфавитном порядке со ссылками на одну или несколько соответствующих предмету страниц. Индекс в базе данных работает точно так же в том смысле, что он направляет запрос в точности туда, где хранятся нужные данные.
![]() Как быстрее найти нужную информацию в книге — перелистывая книгу страница за страницей, либо находя номер нужной страницы в предметном указателе? Конечно, использование предметного указателя оказывается более эффективным. Если книга большая, то таким образом можно сэкономить немало времени. Предположим, что в книге всего несколько страниц. В таком случае, конечно, проще проверить все страницы вместо того, чтобы скакать туда-сюда к
предметному указателю и страницам с основным текстом. Когда индексы не используются, выполняется то, что называется полным сканированием таблиц — нечто подобное перелистыванию книги постранично от начала до конца. Полное сканирование таблиц будет обсуждаться в ходе урока 17, "Повышение эффективности работы с базой данных".
Как быстрее найти нужную информацию в книге — перелистывая книгу страница за страницей, либо находя номер нужной страницы в предметном указателе? Конечно, использование предметного указателя оказывается более эффективным. Если книга большая, то таким образом можно сэкономить немало времени. Предположим, что в книге всего несколько страниц. В таком случае, конечно, проще проверить все страницы вместо того, чтобы скакать туда-сюда к
предметному указателю и страницам с основным текстом. Когда индексы не используются, выполняется то, что называется полным сканированием таблиц — нечто подобное перелистыванию книги постранично от начала до конца. Полное сканирование таблиц будет обсуждаться в ходе урока 17, "Повышение эффективности работы с базой данных".
Созданный для таблицы индекс сохраняется отдельно от этой таблицы. Главным назначением индекса является повышение скорости извлечения данных. Создание или удаление индексов на сами данные не влияет. Удаление индекса может лишь замедлять процесс получения данных. Для хранения индекса требуется физическая память и нередко индекс разрастается больше самой таблицы, для которой он был построен.
При создании индекса таблицы в него заносится информация о размещении данных того столбца, по которому происходит индексирование. Когда в таблицу добавляются записи, в индекс тоже заносятся соответствующие данные. При выполнении запроса, в котором либо в условии этого запроса, либо в выражении ключевого слова WHERE присутствует столбец, по которому выполнено индексирование, сначала происходит поиск в индексе. Если подходящее значение в индексе будет найдено, индекс возвратит точное местоположение нужных данных в таблице. На рис. 16.1 показано, как функционирует индекс.
Рассмотрим для примера следующий запрос.
SELECT *
FROM TABLE_NAME
WHERE NAME = 'SMITH';
Как показано на рис. 16.1, для ускорения поиска значений 'SMITH' в таблице используется индекс, построенный по значениям столбца NAME (фамилия). После того, как для фамилии места соответствующих записей в таблице определены, данные могут быть извлечены очень быстро. В индексе данные упорядочены по алфавиту — здесь, например, это касается фамилий.
В случае отсутствия индекса тот же самый запрос привел бы к полному сканированию таблицы, и значит, в поисках нужных данных (фамилии SMITH) была бы прочитана каждая строка таблицы.
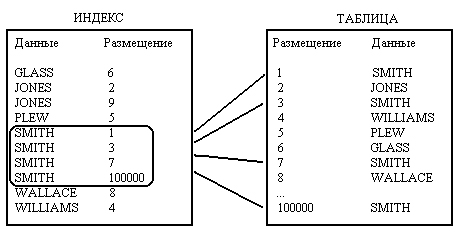
Рис. 16.1. Доступ к таблице с помощью индекса
Форма оператора CREATE INDEX, как формы многих других операторов SQL, может варьироваться в зависимости от конкретной реализации языка. Многие реализации поддерживают следующий синтаксис оператора.
![]() CREATE INDEX имя_индекса ON имя_таблицы
CREATE INDEX имя_индекса ON имя_таблицы
Очень большие отличия для различных реализаций языка наблюдаются в допустимых опциях оператора CREATE INDEX. Некоторые реализации SQL допускают опции управления памятью (как в операторе CREATE TABLE), опции упорядочения (DESC | ASC), а также использование кластеров. Чтобы выяснить корректный синтаксис, необходимо обратиться к документации по той конкретной реализации языка, которую вы используете.
Для таблиц базы данных можно создать индексы нескольких типов, но все индексы служат одной цели — ускорению работы с базой данных посредством ускорения поиска данных. На этом уроке мы рассмотрим простые индексы (построенные по данным одного столбца), составные или композитные индексы (комбинирующие данные нескольких столбцов) и уникальные индексы.
 В некоторых реализациях SQL индексы могут создаваться уже при создании таблицы. Большинство реализаций языка для создания индексов предлагает специальную команду, отличную от команды CREATE INDEX. Наличие или отсутствие специальной команды для создания индексов, как и ее синтаксис, можно уточнить по документации используемого вами языка.
В некоторых реализациях SQL индексы могут создаваться уже при создании таблицы. Большинство реализаций языка для создания индексов предлагает специальную команду, отличную от команды CREATE INDEX. Наличие или отсутствие специальной команды для создания индексов, как и ее синтаксис, можно уточнить по документации используемого вами языка.
Индексирование по данным одного столбца таблицы является самым простым и, в то же время, наиболее часто используемым типом индексирования. Простой индекс — это индекс, создаваемый по данным одного столбца таблицы. Базовый синтаксис оператора для создания такого индекса выглядит следующим образом.
![]() CREATE INDEX имя_индекса
CREATE INDEX имя_индекса
ON имя_таблицы (имя_столбца)
Например, если необходимо создать индекс таблицы EMPLOYEE_TBL по фамилиям служащих, то это можно сделать с помощью следующей команды.
CREATE INDEX NAME_IDX
ON EMPLOYEEJTBL (LAST__NAME) ;
Следует внимательно отнестись к планированию таблиц и их индексов. Не думайте, что создав индекс, вы решите все проблемы производительности использования базы данных. Иногда индекс может не ускорять, а тормозить работу. Кроме того, индекс занимает дисковое пространство.
![]() Использование простого индекса оказывается наиболее эффективным в том случае, когда соответствующий индексу столбец часто используется в условиях запросов в выражениях ключевого слова WHERE. Хорошими кандидатами для использования в индексах являются столбцы с табельными номерами, серийными номерами, или созданными системой порядковыми номерами (счетчиками)
Использование простого индекса оказывается наиболее эффективным в том случае, когда соответствующий индексу столбец часто используется в условиях запросов в выражениях ключевого слова WHERE. Хорошими кандидатами для использования в индексах являются столбцы с табельными номерами, серийными номерами, или созданными системой порядковыми номерами (счетчиками)
![]() Уникальные индексы используются не только для ускорения поиска данных, но и для обеспечения их целостности. Наличие уникального индекса не позволит ввести в таблицу дубликаты записей. В то же время уникальный индекс работает точно так же, как и обычный. Синтаксис соответствующего оператора следующий.
Уникальные индексы используются не только для ускорения поиска данных, но и для обеспечения их целостности. Наличие уникального индекса не позволит ввести в таблицу дубликаты записей. В то же время уникальный индекс работает точно так же, как и обычный. Синтаксис соответствующего оператора следующий.
![]() CREATE UNIQUE INDEX имя_индекса
CREATE UNIQUE INDEX имя_индекса
ON имя_таблицы (имя__столбца)
Например, чтобы создать уникальный индекс таблицы EMPLOYEE_TBL по фамилиям служащих (LAST_NAME), используйте следующую команду.
CREATE UNIQUE INDEX NAME__IDX
ON EMPLOYEEJTBL (LAST_NAME);
Единственной проблемой при создании уникального индекса является требование уникальности значений соответствующего столбца в таблице — требование, выполняющееся далеко не для всех столбцов. Но уникальный индекс можно создавать для столбцов типа идентификационного кода, поскольку такие номера очевидно уникальны для каждой персоны.
У вас может возникнуть вопрос: "А если идентификационный код не является в таблице ключом?" Индекс неявно создается при определении ключа таблицы. Но в конкретной компании данные могут обрабатываться по внутреннему табельному номеру, а идентификационные коды служащих использоваться только для документов, связанных с отчислениями по налогам. Тогда логичнее будет создать индекс по табельному номеру и обеспечить его уникальность.
Уникальный индекс можно создать только по тому столбцу таблицы, данные которого уникальны.
![]() Составной индекс — это индекс, составленный по значениям нескольких столбцов таблицы. При создании составного индекса уже следует учитывать вопросы производительности базы данных, поскольку в данном случае порядок столбцов в условии индекса может сильно влиять на скорость извлечения данных. Общее правило для повышения производительности таково: более ограничивающее значение должно идти первым. Однако первым должен указываться столбец, наличие которого всегда предполагается в условиях выбора. Синтаксис соответствующего оператора следующий.
Составной индекс — это индекс, составленный по значениям нескольких столбцов таблицы. При создании составного индекса уже следует учитывать вопросы производительности базы данных, поскольку в данном случае порядок столбцов в условии индекса может сильно влиять на скорость извлечения данных. Общее правило для повышения производительности таково: более ограничивающее значение должно идти первым. Однако первым должен указываться столбец, наличие которого всегда предполагается в условиях выбора. Синтаксис соответствующего оператора следующий.
![]() CREATE INDEX имя_индекса
CREATE INDEX имя_индекса
ON имя_таблицы (столбец1, столбец2)
Вот пример создания составного индекса.
CREATE INDEX ORD_IDX
ON ORDERS_TBL (CUST_ID, PROD_ID);
В этом примере создается составной индекс по значениям двух столбцов таблицы ORDERSJTBL — столбцов CUST_ID и PROD_ID. Предполагается, что значения этих столбцов будут часто одновременно использоваться в условиях ключевого слова WHERE в запросах.
![]() Использование составного индекса оказывается наиболее эффективным в том случае, когда соответствующие индексу столбцы часто одновременно используются в условиях запросов в выражениях ключевого слова WHERE.
Использование составного индекса оказывается наиболее эффективным в том случае, когда соответствующие индексу столбцы часто одновременно используются в условиях запросов в выражениях ключевого слова WHERE.
При решении вопроса о выборе типа создаваемого индекса примите во внимание ожидаемую частоту использования соответствующего столбца (или столбцов) в условиях запросов в выражениях ключевого слова WHERE. Если в условиях будет использоваться один столбец, следует выбрать простой индекс, а если предполагается часто использовать несколько столбцов одновременно, лучше построить составной индекс.
![]() Неявные индексы — это индексы, создаваемые автоматически сервером базы данных при создании объектов. Например, автоматически создаются индексы для ключей и ограничений типа уникальности. Зачем создаются такие индексы? Представьте, что сервером базы данных являетесь вы. Пользователь добавляет в базу данных информацию о новом товаре. Код товара является ключом таблицы, и это значит, что код товара должен быть уникальным. Чтобы быстро проверить уникальность вводимого пользователем кода среди сотен или тысяч записей, коды товаров должны быть индексированы. Поэтому при создании ключа или задании условий уникальности для вас автоматически создается соответствующий индекс.
Неявные индексы — это индексы, создаваемые автоматически сервером базы данных при создании объектов. Например, автоматически создаются индексы для ключей и ограничений типа уникальности. Зачем создаются такие индексы? Представьте, что сервером базы данных являетесь вы. Пользователь добавляет в базу данных информацию о новом товаре. Код товара является ключом таблицы, и это значит, что код товара должен быть уникальным. Чтобы быстро проверить уникальность вводимого пользователем кода среди сотен или тысяч записей, коды товаров должны быть индексированы. Поэтому при создании ключа или задании условий уникальности для вас автоматически создается соответствующий индекс.
Когда следует создавать индекс?
Уникальные индексы используются неявно для работы с ключевыми полями. Внешние ключи тоже обычно неплохие кандидаты для использования в индексах, поскольку внешние ключи часто используются для связывания таблиц. Индексы должны использоваться для большинства столбцов, если не для всех, используемых для связывания таблиц.
Неплохо построить индексы и для тех столбцов, которые часто используются в выражениях ключевых слов ORDER BY и GROUP BY. Например, если вы используете сортировку по фамилиям служащих, неплохо иметь какой-нибудь индекс по столбцу с фамилиями. Это автоматически разместит фамилии по алфавиту (в индексе) и поэтому ускорит сортировку и вывод запрашиваемых данных.
Более того, следует создать индексы по столбцам с большим числом уникальных значений в них, а также по столбцам, которые при использовании в качестве фильтров в выражениях WHERE возвращают небольшое количество строк. Здесь наилучшей рекомендацией будет метод проб и ошибок. Точно также, как перед использованием
базы данных ее нужно протестировать, прежде, чем использовать индексы, протестируйте их. Во время такого тестирования должны быть опробованы различные комбинации индексов, работа без индексов, простые и составные индексы. По использования индексов однозначных рекомендаций, к сожалению, нет. Для эффективного использования индексов требуется хорошее понимание структуры и связей базы данных, требований запросов и транзакций, да и самих данных.
Когда не следует создавать индекс?
Хотя задачей использования индексов и является повышение скорости работы с базой данных, бывают ситуации (перечисленные ниже), когда использования индекса лучше избежать.
• Не следует использовать индексы для небольших таблиц.
• Не следует использовать индексы по столбцам, возвращающим большой процент данных таблицы при использовании их в качестве фильтров в условиях ключевого слова WHERE. Например, в предметный указатель книги нет смысла помещать ссылки на слова типа "поэтому" или "для".
• Можно индексировать таблицы, по отношению к которым часто используются операции по обновлению данных. Однако индексы сильно тормозят выполнение такого рода пакетных операций. Конфликт здесь можно разрешить удалением индекса перед выполнением операции и созданием нового индекса после ее завершения.
• Не следует использовать индексы по столбцам, в которых имеется много значений
NULL.
• Не следует использовать индексы по столбцам, значения которых часто обновляются. Усилия по обслуживанию индекса при этом непомерно велики.
![]() Следует избегать создания индексов для таблиц с ключами очень большой длины, поскольку скорость работы с такими таблицами заметно падает из-за больших объемов ввода/вывода
Следует избегать создания индексов для таблиц с ключами очень большой длины, поскольку скорость работы с такими таблицами заметно падает из-за больших объемов ввода/вывода
Из рис. 16.2 видно, что использование индекса, построенного на данных столбца для классификации по признаку пола, не является оправданным. Рассмотрим, например, следующий запрос к базе данных.
SELECT *
FROM ИМЯ_ТАБЛИЦЫ
WHERE GENDER = 'ЖЕН';
Взглянув на рис 16.2, вы увидите, что этот запрос вызывает непрерывный поток обращений от таблицы к индексу и наоборот. Из-за того, что условием WHERE GENDER = 'ЖЕН' (или МУЖ) возвращается большой объем данных, серверу базы данных придется постоянно читать сначала данные из индекса, затем соответствующую строку из таблицы и т. д. В данном случае гораздо более эффективным было бы простое сканирование всех данных таблицы, поскольку значительная ее часть все равно должна быть прочитана.
Главное то, что не следует использовать индекс по столбцу, возвращающему в условиях запроса большой процент данных таблицы. Другими словами, не создавайте индексы по столбцам типа пола или другим столбцам, число различных значений в которых невелико.
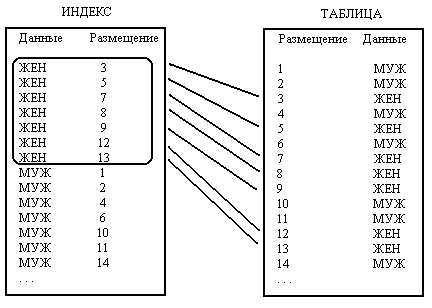
Рис. 16.2. Случай, когда создавать индекс не следует
![]() Индексы могут значительно ускорить работу с базой данных, но они могут также и сильно затормозить ее Снова напомним, что следует избегать создания индексов по столбцам, содержащим небольшое число различных значений, таких как признаки пола, город проживания и т п
Индексы могут значительно ускорить работу с базой данных, но они могут также и сильно затормозить ее Снова напомним, что следует избегать создания индексов по столбцам, содержащим небольшое число различных значений, таких как признаки пола, город проживания и т п
Удалить индекс просто. Проверьте точный синтаксис соответствующего оператора по документации. Можно с уверенностью утверждать, что в большинстве реализаций SQL для удаления индексов используется команда DROP. При удалении индекса всегда следует опасаться существенного понижения скорости работы с базой данных. Но не забывайте, что после удаления индекса всегда есть возможность воссоздать его. Время от времени индексы следует перестраивать для того, чтобы не допускать их излишней фрагментации. Часто бывает полезно поэкспериментировать с использованием индексов с целью ускорения работы базы данных — создать ряд новых индексов, удалить некоторые из старых, снова их воссоздать с некоторыми модификациями или без таковых.
Вы узнали о том, что использование индексов может повысить скорость выполнения запросов и транзакций базы данных. Индексы базы данных, как и предметный указатель книги, позволяют быстрее найти нужные данные по ссылкам на них. Чаще всего для создания индексов используется команда CREATE INDEX. Существует несколько типов индексов, зависящих от конкретной реализации SQL. Уникальные индексы, простые индексы и составные индексы относятся к наиболее часто встречающимся. При выборе типа индекса для использования в базе данных приходится учитывать целый рад факторов. Эффективное решение часто можно найти только в результате экспериментирования на базе четкого понимания структуры данных и связей между ними, а также терпения: все это поможет вам сэкономить силы и время.
Увеличивает ли индекс объем дискового пространства, необходимый для хранения данных таблицы?
Да. Сам индекс требует физической памяти для своего хранения. На самом деле индекс может оказаться значительно больше самой таблицы, для которой он был создан.
Если перед выполнением пакетных операций обновления данных для ускорения их выполнения индекс удалить, сколько времени впоследствии потребуется для его восстановления?
Здесь ответ зависит от множества факторов, таких как объем удаленного индекса, возможностей процессора и всего аппаратного обеспечения системы в целом.
Должны ли все индексы быть уникальными?
Нет. Уникальные индексы используются для того, чтобы не допустить дублирования значений. Но могут быть причины, по которым в таблице могут допускаться повторы данных.
Задания практических занятий разделены на тесты и упражнения. Тесты предназначены для проверки общего уровня понимания рассмотренного материала. Упражнения дают возможность применить на практике идеи, обсуждавшиеся в ходе текущего урока, в комбинации с идеями из предыдущих урйков. Мы рекомендуем ответить на тестовые вопросы и выполнить упражнения прежде, чем продолжать дальнейшее чтение книги. Ответы можно проверить по Приложению Б, "Ответы".
1. Каковы главные недостатки использования индексов?
2. Почему важен порядок столбцов в составном индексе?
3. Следует ли создавать индекс по столбцу, в котором часто встречается значение NULL?
4. Является ли основной целью использования индекса недопущение повторений данных в таблице?
5. Верно ли следующее утверждение: "Главной причиной использования составных индексов является использование в таких индексах значений, по отношению к которым используются итоговые функции?"
1. Следует ли создавать индекс в следующих случаях, и если да, то какого типа индекс будет предпочтительнее?
а. Таблица имеет не много записей и несколько столбцов.
б. Таблица средней величины, но в ней не допускаются повторения.
в. Очень большая таблица, несколько столбцов которой используется в фильтрахключевого слова WHERE.
г. Большая таблица с множеством столбцов, предполагающая частые обновления данных.