ПРИЛОЖЕНИЕ 1.
Основы языка программирования C++
Знакомство с языком программирования C++ хотелось бы начать с цитаты из книги разработчика языка Бьерна Страуструпа:
"Язык программирования служит двум связанным между собой целям: он дает программисту аппарат для задания действий, которые должны быть выполнены, и формирует концепции, которыми пользуется программист, размышляя от том, что делать...
Язык поддерживает стиль программирования, если он предоставляет соответствующие средства и делает удобным (т. е. легким, безопасным и эффективным) использование этого стиля... Например, можно писать структурированные программы на языке Fortran и объектно-ориентированные программы на С, но это неизменно будет трудно (во втором случае — особенно), поскольку они не поддерживают эти парадигмы.
Язык программирования C++ был разработан так, чтобы в дополнение к традиционной технологии программирования на С поддерживать абстракцию данных и объектно-ориентированное программирование при определяющей роли следующих пяти ограничений, первое из которых выражает чисто эстетический и логический идеалы, следующие два — идеал минимальности и, наконец, два последних могут быть охарактеризованы как "то, что вам не нужно, скорее всего не причинит ущерба":
Однако сказанное не означает, что программистам навязывается определенный стиль программирования."
После знакомства с теми общими положениями, которые хотел вложить в C++ его создатель, перейдем к знакомству с собственно языком.
Символ комментария //, действующий до конца строки, является теперь составной частью языка, а не только расширением Microsoft, как это было для языка С.
Ключевые слова, характерные только для C++, приведены в табл. П1.1.
Таблица П1.1. Ключевые слова языка C++
|
bad_cast bad_typeid bool catch class const c onst_cast delete dynamic_cast except |
explicitfalse finally friend inline mutable namespace new operator private |
protected public reinterpret_cast signed static_cast template this throw true |
try typejnfo typeid typename using virtual volatile xalloc |
Как вы помните, для определения константы в языке С использовалась директива препроцессора #define, что было достаточно удобно. Отрицательной стороной такого определения является то, что при этом нельзя указать тип, которому принадлежит константа. В C++ введено новое ключевое слово const, позволяющее создавать константы. При этом явным образом указывается тип, который компилятор в дальнейшем может проверить.
const float PI = 3.1415926;
Константную переменную нельзя модифицировать, и поэтому попытка изменить ее вызывает ошибку во время компиляции. Константой можно объявить и указатель. При этом изменять нельзя только значение самого указателя, а объект (переменную), на который он указывает, менять можно:
int nValue;
const int *ptrVar = &nValue;
*ptrVar += 7; // Такое действие допустимо
ptrVar++; // А вот так нельзя изменять значение самого указателя
Ключевое слово const можно применить и к функции:
int anyFunc(...) const;
...
int anyFunc(...) const
{
...
}
В этом случае функция считается "только для чтения", и нельзя модифицировать объект, для которого она вызывается.
Примечание
Ключевое слово const необходимо указывать и при объявлении и при определении функции.
В C++ допускаются объявления внутри блоков и после программных операторов, что позволяет определять (объявлять) объект в том месте программы, где он используется первый раз — во многих случаях это улучшает читабельность программы.
void myFunc()
{
int nFirstVar;
nFirstVar++;
// Другие операторы функции
...
float fSecondVar =7.0;
...
// Остальные операторы функции
}
Кроме того, можно определить и инициализировать переменную непосредственно внутри формального описания управляющей структуры:
for(int iCount = 0; iCount < MAX_COUNT; iCount++) {...}
Примечание
Определенная таким образом переменная не входит в блок управляющей структуры и поэтому действует до конца всего блока, в котором используется эта структура. Поэтому следующая конструкция недопустима:
for(int iCount = 0; iCount < MAX_COUNT1; iCount++)
{
...
}
for( int iCount = 0; iCount < MAX_COUNT2; iCount++)
{
...
}
Для того чтобы функция могла вернуть более одного значения, в языке С необходимо было передать ей в качестве параметра указатель на те переменные, значения которых требуется получить. Зачастую это служило источником достаточно большого количества ошибок, особенно у начинающих программистов, когда вместо адреса в функцию передавалось значение переменной. В C++ можно определить ссылку на переменную или объект класса. Ссылка содержит адрес объекта, но используется так, как будто она представляет сам объект. Для объявления ссылки используется оператор &:
double dVar; // Определяет переменную типа double
double SrdVar = dVar; // Определяет ссылку типа double
Такая переменная при определении должна быть обязательно проинициализирована.
Наиболее очевидным применением ссылок является обеспечение передачи функции адреса вместо самой переменной (иногда это называется передачей параметра по ссылке), что позволяет избежать копирования параметров, передаваемых функции в качестве аргументов, в стек:
struct BigStruct{
int array[1000];
}stObject;
void funcl(BigStruct bs) ; // В качестве параметра передается
// значение
void func2(BigStruct *bs); //В качестве параметра передается
// указатель
void func3(BigStruct Sbs); // В качестве параметра передается ссылка
Вызов функции funcl связан с копированием в стек всех 4000 байт (для версии Visual C++ 6.0) структуры BigStruct. Ситуация меняется в двух других случаях, когда передается только адрес структуры. Они различаются тем, что в последнем случае мы работаем с этим адресом, как будто это недосредственно переменная, и дополнительных действий по снятию адреса не требуется.
Имена перечислений, структур и объединений
В C++ имя перечисления, структуры или объединения является именем типа. Это упрощает нотацию, поскольку не нужно использовать ключевые слова enum, struct и union перед именем соответствующего типа. Таким образом, в C++ выражения вида
struct Fruits{
// Компоненты структуры
};
Fruits stApple; // Определение переменной типа Fruits .
являются допустимыми.
В C++ встроены специальные операторы для управления памятью — new и delete. Они чрезвычайно удобны для динамического создания и удаления переменных, массивов и объектов классов и заменяют функции malloc, alloc и free, используемые в С.
Определены три способа использования оператора new:
new t_name; // Выделяется память под объект типа
t_name new t_name(initValue); // Выделяется память под объект типа
// t_name с одновременной инициализацией
new type_name[size]; // Выделяется память под size объектов
// типа t_name
Для первого способа существует эквивалентная запись:
new (type_name);
Этот оператор запрашивает у системы память, необходимую для размещения объекта, и возвращает на нее указатель.
Для удаления объекта, созданного с помощью оператора new, необходимо выполнить оператор delete, который может использоваться двумя способами:
delete vObject; // Освободить память, занятую объектом
delete [] vObject; // Освободить память, занятую массивом объектов
Примечание
Применение оператора delete к неинициализированному указателю является ошибкой, за которой должен следить сам программист.
Спецификатор inline предназначен для использования перед объявлением функции, чтобы компилятор помещал ее код непосредственно в место вызова:
// Код этой функции будет подставлен в каждом месте вызова
inline void swap(float &a, float &b);
При таком объявлении функции в каждом месте вызова появится ее локальная копия. В языке С этого же эффекта можно было добиться при помощи директивы препроцессора #define, неправильное использование которой зачастую служит источником ошибок.
Примечание
Использование спецификатора inline не больше чем просьба к компилятору, которую он может удовлетворить или нет. Кроме того, стандарт оговаривает случаи, когда эта просьба никогда не будет удовлетворена:
• если это рекурсивная функция;
• если имеется вызов из определенной ранее встроенной функции;
• если в функции имеются циклы.
В C++ есть еще один способ встраивания функций, но его мы рассмотрим после того, как познакомимся с классами.
В С каждая функция должна иметь уникальное имя. В C++ тип функции так же важен, как и ее имя. Перегрузка позволяет использовать одно и то же имя для реализации разных функций. Это означает, что можно иметь несколько функций с одним и тем же именем", но с различным числом и типами аргументов:
int sort(char **str); // Сортирует массив строк
int sort(int*, int); // Сортирует массив целых чисел
int sort(double*, double); // Сортирует массив вещественных чисел
Поскольку число и типы аргументов в каждой функции отличаются друг от друга, то C++ без труда автоматически выбирает нужную функцию.
Перегрузка функций позволяет программисту маскировать различия между типами аргументов. Она также является одной из причин замены макросов #define на встраиваемые функции. Макросы не имеют типа и поэтому не могут быть перегружены, тогда как встраиваемые функции позволяют реализовать этот механизм.
Задание параметров функции по умолчанию
В дополнение к возможностям, имеющимся в С, в языке C++ появилась еще одна — теперь при объявлении или определении можно задавать значения некоторых параметров функции по умолчанию:
float Multi(float fFirst, float fSecond,
float fThird —I, float gFourth = 1)
{
return (fFirst * fSecond * fThird * gFourth);
}
При вызове этой функции такие параметры можно не указывать:
...
float fResult;
fResult = Multi(2, 3, 4, 5); // Произведение четырех чисел:
// fResult = 120
fResult = Multi(2, 3, 4); // Произведение трех чисел:
// fResult = 24
fResult = Multi(2, 3); // Произведение двух чисел:
// fResult = 6
...
Эта возможность чрезвычайно удобна в том случае, когда при вызовах функции часто используются одни и те же значения некоторых параметров.
Здесь следует учитывать одно ограничение: присваивание значений, заданных по умолчанию, должно выполняться справа налево. Поэтому следующая запись недопустима:
double func(double dArgl = 7, double dArg2); // Так нельзя
Если необходимо указать значение по умолчанию для dArgl, то и dArg2, в данном случае, тоже нужно присвоить значение по умолчанию.
В C++ определены следующие три дополнительные операции:
:: Уточнение области действия
.* Прямое обращение к компоненту класса
->* Косвенное обращение к компоненту класса
Для устранения конфликта имен используется новая операция уточнения области действия — ::. В языке С, если локальная и глобальная переменные имели одинаковые имена, то доступ к глобальной переменной был закрыт. В C++ доступ к ней возможен путем применения операции ::.
int iVariable; // Глобальная переменная
void myFunc()
{
int iVariable; // Локальная переменная
...
::iVariable++; // Увеличиваем значение глобальной переменной
...
iVariable- -; // Уменьшаем значение локальной переменной
...
}
Эта операция может применяться также к статическим (static) компонентам структур и классов.
Операция прямого обращения к компоненту класса .* устанавливает указатели так, что в результате выполнения операции они указывают на компоненты данного класса:
(ptrToObject.*memberFunc)(7); // Вызывает метод memberFunc для
// объекта, на который указывает ptrToObject
Операция косвенного обращения к компоненту класса ->* устанавливает указатели так, что в результате выполнения операции они указывают на ука- затели компонентов данного класса:
(ptr2Objedt->*ptr2MemberFunc-) (7);// Вызывает метод ptr2MemberFunc
// для объекта, на который
// указывает ptr20bject
В язык C++ включены дополнительные предопределенные потоки. Для терминального и файлового ввода/вывода предусмотрены три стандартных потока: cin, cout и cerr. Эта возможность позволяет легко настроить операции ввода/вывода в соответствии с требованиями приложения:
...
float sm = 0;
cout « "сантиметры = "; // Выводим строку в поток cout
cin » sm; // Получаем значение из потока cin
cout « sm « "соответствуют " « sm / 2.54 « "дюймам";
...
В результате выполнения последней строки приведенного фрагмента на экран будет выведена, например, следующая строка:
17.78 sm соответствуют 7 дюймам
После того как мы познакомились с усовершенствованиями, внесенными в язык C++, можно переходить к фундаментальным новшествам этого мощнейшего и очень удобного языка программирования.
Самое существенное улучшение по сравнению с языком С касается концепции объектно-ориентированного программирования. Это
Теперь перейдем к рассмотрению применительно к языку C++ трех ключевых идей объектно-ориентированного программирования: инкапсуляции, наследования и полиморфизма и теснейшим образом связанного с ними понятия класса.
Классы представляют собой первичный механизм, позволяющий реализовать скрытие данных, абстракцию данных и наследование — те самые свойства, которые делают C++ объектно-ориентированным языком.
Классы C++ предусматривают создание расширенной системы предопределенных типов. Каждый тип класса представляет уникальное множество объектов и операций над ними, а также операций, используемых для создания, манипулирования и уничтожения таких объектов. Могут быть объявлены производные классы, наследующие компоненты одного или нескольких базовых (порождающих) классов.
Но обо всем по порядку.
Для определения классов используются три ключевых слова: struct, union и class. Каждый класс, определенный посредством одного из этих ключевых слов, включает в себя функции — называемые методами или компонентными функциями (member function), и данные — называемые элементами данных (class members). Так же, как и для структур и объединений, каждому классу присваивается некоторое имя (лучше содержательное), которое становится идентификатором нового типа данных и может использоваться для объявления объектов (или экземпляров) этого типа (рис. П1.1).
Описание класса начинается с ключевого слова <ключ_класса>, в качестве которого можно использовать struct, union, class и непосредственно за которым следует имя класса — <имя_класса>:
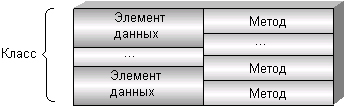
Рис. П1.1. Инкапсуляция элементов и методов класса
ключ_класса имя_класса <: базовый_список>
{
// Здесь объявляются как методы, так и элементы класса
<Компоненты_класса>
};
Необязательный базовый_список содержит базовый класс (или классы), из которого имя_класса заимствует элементы и методы. Необязательный список компонентов объявляет элементы и методы класса и, при необходимости, спецификаторы доступа.
После того как новый уникальный тип данных объявлен, можно определять объекты данного типа (класса), а также объекты, являющиеся производными от него:
class Sample{
unsigned uData; // элемент данных
unsigned readDataO; // метод (компонентная функция)
...
};
Sample cllnstl, // Переменная типа Sample
*pcllnst2 = scllnstl, // Указатель на Sample
arlnst[7]; // Массив элементов типа Sample
Допускаются также неполные объявления класса:
class Simple;
которые разрешают некоторые ссылки к именам классов до того, как классы будут полностью определены.
Обращаться к компонентам класса можно, указав имя объекта — имя элемента или метода, и разделив эти имена операцией "." (точка), или, при использовании указателя — операцией "->":
cllnstl.uData = 7;
unsigned uRes = pc!nst2->readData();
Примечание
Несмотря на то, что приведенные выражения правильны, при компиляции будет выдано сообщение об ошибке, поскольку в соответствии с принципом скрытия данных, установленным по умолчанию, доступ и к элементу данных, и к методу невозможен.
Чуть раньше я уже говорил о том, что в C++ возможно встраивание функций посредством спецификатора inline, который является не больше, чем "просьбой" к компилятору, которую тот может как удовлетворить, так и проигнорировать.
Для методов класса возможно неявное выражение такой просьбы:
class MyClass{
... // Объявления переменных и методов
float fVar;
float* func(); {return fVar;} // inline по умолчанию
};
что эквивалентно следующей записи:
inline float* MyClass::func(); {return fVar;}
Очевидно, что для встраиваемых функций нельзя говорить об их адресе.
В отличие от обычных функций языка С (да и C++ тоже), нестатические методы классов в C++ имеют одну неявную локальную переменную. Эта переменная даже имеет специальное имя — this. И хотя на практике она используется достаточно редко, однако в некоторых случаях наличие этой переменной бывает полезно, в чем мы с вами убедимся при знакомстве с библиотекой MFC. Фактически же this — это указатель на текущий объект класса.
Вы, наверное, обратили внимание на то, что в последнем абзаце я употребил слово "нестатического", которое требует некоторых пояснений.
При объявлении данных и методов класса может быть использован спецификатор класса памяти static. Вспомните, что языке С этот спецификатор ограничивает область видимости переменной или функции одним модулем — налицо попытка введения некоторого ограничения доступа. В C++ компоненты класса, перед которыми стоит это ключевое слово, называются статическими и обладают свойствами, отличными от свойств "обычных" элементов. Для наглядности рассмотрим небольшой пример (рис. П1.2):
class MyClass{
int nVarUnStatic; // обычная переменная
static int nVarStatic; // статическая переменная
// объявления других переменных и методов
};
MyClass cllnstancel, *pcllnstance2;
Таким образом, если для нестатических (обычных) элементов для каждого объекта класса создается отдельная копия, и обращение, например, к элементу nVarUnStatic осуществляется по обычным правилам:
clInstancel.nVarUnStatic++; // правильно
pclInstancel->nVarUnStatic++; // правильно
то для статического элемента можно просто задать имя класса совместно с модификатором области действия:
MyClass::nVarStatic++; // правильно
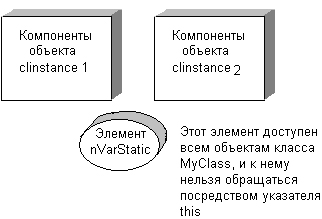
Рис. П1.2. Распределение памяти для статических и нестатических переменных
Однако это еще не все. В отличие от нестатических элементов, память под которые выделяется при создании объекта класса, для статических должно быть отдельное определение, отвечающее за распределение памяти и инициализацию, например, такое:
static MyClass:rnVarStatic;
Основное назначение статических элементов состоит в том, чтобы отслеживать данные, общие для всех объектов класса, а также для уменьшения числа видимых глобальных имен.
По аналогии со статическими элементами данных, статические методы не ассоциируются с каким-либо конкретным объектом и, соответственно, не имеют указателя this. Такие методы вызываются просто по имени класса, например, так:
MyClass::func() ;
Поскольку статический метод не имеет указателя this, из него нельзя обращаться к элементам данных, не задавая в явном виде конкретный объект. В то же время допустимо непосредственное обращение к статическим компонентам класса. Осталось сказать еще о двух ограничениях:
Примечание
Для элементов данных и методов класса недопустимо использование каких-либо других спецификаторов класса памяти, кроме static.
В языке C++ разграничение доступа получило свое логическое продолжение. Рассмотрим этот вопрос более подробно.
Разграничение доступа (скрытие данных и методов)
Определив структуру, объединение или класс, можно создавать объекты этого класса (структуры, объединения) и манипулировать ими, используя методы. При этом некоторые данные и методы, инкапсулированные в одном классе, можно сделать недоступными вне реализации класса, а другие могут быть доступны из любого места программы.
Элементы структур, объединений и классов получают атрибуты доступа либо по умолчанию, либо при использовании какого-либо из трех спецификаторов доступа: public, protected или private, которые имеют следующий смысл:
public
Компонент доступен для любой функции
protected
Компонент может быть использован методами или "друзьями" класса, в котором он объявлен, а также производных от него, но только в объектах производного класса
private
Компонент может быть использован только методами или "друзьями" класса, в котором он объявлен
Определены следующие значения доступа по умолчанию для компонентов классов, структур и объединений:
Спецификатор доступа, заданный явно или по умолчанию, остается действительным для всех последующих объявлений компонентов, пока не встретится какой-либо другой спецификатор доступа.
class MyClass{
... // Объявления переменных и методов — по умолчанию
private
protected: // Изменяем атрибуты доступа
float fVar;
public: // Еще раз изменяем атрибуты доступа
float* func(); {return fVar;}
};
Спецификаторы доступа могут быть перечислены и сгруппированы в любой удобной для вас последовательности.
Теперь вам стало понятно, почему в примере на стр. 580 компилятор выдаст сообщение об ошибке — доступ к частным компонентам класса (что установлено по умолчанию) запрещен. Доступ к элементу данных uData может быть организован, например, так:
class Sample{
// элемент данных
unsigned uData;
public: // изменяем права доступа
// методы (компонентные функции)
unsigned writeData(unsigned uArg);
unsigned readData();
..
} cllnstl, *pclnst2;
Тогда
cllnstl.uData =7; // по-прежнему ошибка!
unsigned uPar = 7;
pc!nst2->writeData(uPar); // теперь правильно
Еще раз повторю. Методы и данные, определенные после ключевого слова public, представляют собой интерфейс класса — они единственные доступны вне класса. Компоненты, определенные после остальных спецификаторов доступа, относятся к внутренней реализации и вне класса недоступны. Различие между компонентами класса, описанными после ключевых слов protected и private, сказываются только при наследовании, которое мы рассмотрим несколько позже.
Рекомендуется всегда явно определять права доступа к компонентам класса.
Иногда ограничение на доступ к частным и защищенным компонентам класса только посредством методов класса оказывается неоправданно жестким. Бывают случаи, когда необходимо разрешить такой доступ.
В языке C++ предусмотрена возможность обеспечить доступ к частным и защищенным компонентам извне класса при помощи ключевого слова friend, которое говорит о том, что следующая за ним функция является "другом" данного класса и имеет полный доступ ко всем его компонентам, не являясь в то же время методом этого класса. Такие дружественные функции не зависят от положения в классе и спецификаторов доступа и ничем другим от обычных методов не отличаются.
class MyClass
{
private:
int nVar;
// Дружественная функция
friend void friendFunc. (MyClass SclArg, int nArg);
public:
// Метод класса
void memberFunc(int nArg);
} ;
// Определения функций
void friend friendFunc(MyClass SclArg, int nArg)
(clArg.nVar = nArg;}
void memberFunc(int nArg) {nVar = nArg;}
// Создаем объект класса
MyClass clObj;
// Обращаемся к частному компоненту класса
friendFunc(clObj, 7);
memberFunc(7);
Дружественные функции класса дают программисту сбалансированный подход к принципу инкапсуляции данных: если методы доступа влекут за собой слишком большие дополнительные издержки, то иногда проще дать некоторой внешней функции права непосредственного доступа к компонентам класса. Более того, одна и та же функция может быть дружественной для нескольких классов.
В качестве дружественной функции может выступать и некоторый метод другого класса:
class MyClassl
{
..
// Метод memberFuncMyClass2 класса MyClass2 объявляется дружественным
// классу MyClassl
friend void MyClass2::memberFuncMyClass2(...);
...
};
По аналогии с функциями и методами можно объявить дружественным весь класс. При этом все методы такого дружественного класса смогут обращаться ко всем компонентам класса:
class MyClass
{
...
// Класс MyFriend объявляется дружественным классу MyClass
friend class MyFriend;
...
};
И еще два замечания:
1. "Дружба" классов не транзитивна. Другими словами, если класс MyClass 1 друг класса MyClass2, a MyClass2 друг MyClass3, то это не означает, что MyClassl друг MyClass3. Однако "дружба" наследуется, но об этом более подробно после знакомства с наследованием.
2. "Дружба" классов односторонняя, т. е. если класс MyFriend объявлен другом MyClass, то это не означает, что MyClass имеет доступ к частным и защищенным компонентам класса MyFriend. Таким образом, права для доступа к классу может предоставить только автор класса, а не программист, написавший функцию или некоторый другой класс.
Пойдем дальше. Как правило, перед использованием объект должен быть инициализирован. В С этот процесс выполнялся либо автоматически (для глобальных и статических элементов), либо путем определения специальной функции, которая вызывается сразу после создания объекта, до его использования. Аналогичный подход можно использовать и в C++. Однако в нем предусмотрен более гибкий способ.
Среди всех методов любого класса выделяются два, определяющие способы, какими создаются, инициализируются, копируются и разрушаются объекты класса. Речь идет о конструкторах (constructor) и деструкторах (destructor), которые наряду с характеристиками обычных методов обладают и некоторыми уникальными свойствами:
Прежде чем переходить к более подробному знакомству с этими специальными методами классов, рассмотрим правила, по которым происходит создание/уничтожение объектов:
Примечание
Для объектов, память под которые выделяется вызовом malloc (или аналогичной функции), конструктор не вызывается вообще, поскольку в этом случае функция просто не знает, какой конструктор надо запустить (эта функция не принимает никакой информации о типе).
Рассмотрим простой пример, для которого воспользуемся классической функцией main, чтобы избежать дополнительных действий, необходимых для Windows-приложений:
// Простой пример,
// демонстрирующий последовательность вызовов конструкторов
и деструкторов
#include <stdio.h>
#include <string.h>
// Объявляем класс
class Sample{
private: //К этим данным доступ возможен только посредством
методов класса
char *strName;
public: // К этим данным доступ возможен из любого места программы
// Определяем простой конструктор
Sample(char *str){
strName = new char[strlen(str) + 1];
strcpy(strName, str);
printf("Entry in constructor for %s\n", strName);
}
// Определяем деструктор,
-Sample ()
{
printf("Entry in destructor for %s\n", strName);
delete strName;
strName = 0;
}
};
// Определяем первый.глобальный объект
Sample globall ("global #!");
// "Глупая" функция, иллюстрирующая Создание автоматического объекта
void SillyFunc(){
// Определяем объект, локальный для данной функции
Sample fnAuto("automatic function");
printf ("Function SillyFuncO \n") ;
}
int main(int argc, char* argv[])
{
// Определяем первый локальный объект
Sample autol("automatic #1") ;
printf("Begin main()\n");
SillyFunc();
// Определяем второй локальный объект
Sample auto2("automatic #2");
printf("Continue main()\n");
return 0;
}
// Определяем второй глобальный объект
Sample globa!2("global #2");
Результат выполнения программы представлен на рис. П1.3, из которого ясно видна последовательность вызовов конструкторов и деструкторов для глобальных и автоматических объектов.
Пойдем дальше. Конструкторы подчиняются тем же правилам перегрузки, что и любые другие функции. Один и тот же класс может иметь несколько конструкторов, если каждый из них имеет свой собственный список аргументов. При определении объекта будет запущен тот конструктор, с которым совпадает заданный список аргументов.
Примечание
Единственным .ограничением на аргументы конструктора является то, что в качестве них нельзя использовать объект того же класса. Вместо этого можно использовать ссылку на объект.
Некоторые конструкторы играют особую роль.
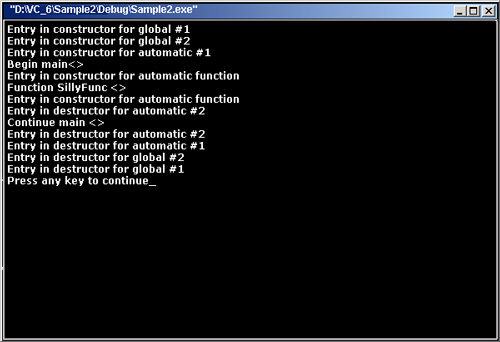
Рис. П1.3. Результат выполнения программы Sample
Конструктор по умолчанию не имеет аргументов и используется, когда объект создается без инициализации его данных:
class MyClass{
public;
MyClass() {}
// Остальные данные и методы
};
Без такого конструктора объекты не могли бы быть определены без задания инициализирующих значений. Если конструктор по умолчанию не объявлен явно, то компилятор автоматически назначает его. Однако, как и все остальное, лучше делать это самому. Он вызывается при таких определениях, как
MyClass clObj;
Как и любая другая функция, конструкторы могут иметь аргументы со значениями, заданными по умолчанию. При этом следует избегать неоднозначностей. Например, в случае определения класса
class MyClass{
public:
MyClass();
MyClass(int nArg =0);
// Остальные данные и методы
};
может возникнуть неопределенность при вызове конструктора
MyClass c!0bjl(7); //можно — однозначно вызывается
//MyClass::MyClass(int)
MyClass clObj2; // нельзя; неоднозначно задано, какой конструктор
// следует вызывать — MyClass: :MyClass (int.)
// или MyClass::MyClass(int nArg = 0)
Аргументом конструктора может быть и сам объект класса. Конструктор в этом случае будет иметь следующий прототип:
MyClass::MyClass(MyClass &);
Такие конструкторы запускаются при копировании данных "старого" объекта во вновь создаваемый:
MyClass clObjl(7); MyClass clObjl = cl0bj2;
Если вы не определили для класса конструктор копирования, то компилятор сделает это за вас. Однако, как обычно, лучше это делать самому.
В отличие от конструкторов, деструктор класса не имеет аргументов и не может быть перегружен. Как было наглядно продемонстрировано в примере на рис. П1.3, деструкторы вызываются строго в обратной последовательности вызова соответствующих конструкторов. Они вызываются автоматически при выходе объекта из блока, в котором были определены. Единственным исключением из этого общего правила является случай, когда объект создается динамически из "кучи", путем вызова оператора new. В этом случае для корректного удаления объекта необходимо явно выполнить оператор delete, который и вызовет необходимый деструктор.
Таким образом, можно подвести предварительные итоги. Понятие класса C++ устанавливает четко определенный интерфейс, который помогает разрабатывать, выполнять; поддерживать и сопровождать программы. Концепция класса органично связана с идеей абстракции данных, при которой данные не связываются ни с каким физическим воплощением, а скорее определяется в терминах методов (функций), выполняемых над ними. С этой точки зрения данные и методы рассматриваются как равные, независимые партнеры.
Следующим ключевым моментом объектно-ориентированного программирования, нашедшим свое воплощение в C++, является возможность создания иерархической структуры классов, которая базируется на наследовании — некоторый класс может передавать свои компоненты другому классу. При этом первый класс называется базовым, а второй — производным классом (или подклассом). Имя базового класса указывается непосредственно после имени производного, до открывающей фигурной скобки:
class BaseClass
{
// Компоненты базового класса
}
class Subclass : public BaseClass
{
// Компоненты производного класса
};
В данном случае производный класс SubClass наследует все компоненты базового, а также содержит любые, определенные непосредственно в нем самом компоненты.
Обратите внимание на ключевое слово public перед именем базового класса, которое определяет тип наследования — в данном случае общедоступный. Помимо такого способа можно также задавать частный (private) тип наследования. Разные типы влияют на доступность компонентов базового класса в производном. Чтобы разобраться в этом вопросе, рассмотрим пример:
class BaseClass
{
public:
11 Общедоступные компоненты базового класса
int nPublBase;
void funcBase();
protected:
// Защищенные компоненты базового класса
int nProtBase;
private:
// Частные компоненты базового класса
int nPrivBase;
};
// class Subclass : public BaseClass // public-наследование
class Subclass : private BaseClass // private-наследование
{
public:
// Общедоступные компоненты производного класса
int nPublSub;
void funcSub();
protected:
// Защищенные компоненты производного класса
int nProtSub;
private:
// Частные компоненты производного класса
int nPrivSub;
};
void main(int argc, char* argv[])
{
BaseClass dBase;
Subclass clSub;
dBase. nPublBase = 7;
dBase. f uncBase () ;
// clSub.nPublBase = 7; // Сшибка, т. к. для класса Subclass даже
// clSub.funcBaseО; // public-компоненты базового класса
// являются private-компонентами
clSub.nPublSub =77;
clSub.funcSub() ;
}
void BaseClass::funcBase()
{
// Имеется доступ ко всем компонентам "своего" класса BaseClass
nPublBase = 1;
nProtBase = 2;
nPrivBase = 3;
}
void Subclass::funcSub()
{
// Имеется доступ только к public и protected-компонентам
// базового класса BaseClass, которые для производного класса
// являются private-компонентами и доступны только для методов класса
nPublBase = 1;
nProtBase = 2;
// nPrivBase =3; // Сшибка; здесь нет доступа к private-компонентам
// Имеется доступ ко всем компонентам "своего" класса
Subclass nPublSub = 4;
nProtSub = 5;
nPrivSub = 6
funcBase () ;
}
Что интересного в этом примере? Прежде всего, обратите внимание, что компонент базового класса, наследуемый как public, сохраняет тот же самый тип доступа.
Несколько по-другому дело обстоит при типе наследования private. Как вы конечно же помните, частный компонент класса доступен только другим компонентам и друзьям класса. Поэтому вполне логичным выглядит то, что такие частные компоненты не доступны в производном классе. Ведь в противном случае программист имел бы возможность получить доступ к таким компонентам, реализовав в производном классе необходимые методы, а это противоречит самой идеологии инкапсуляции.
Однако часто необходимо из производного класса обеспечить доступ к некоторым компонентам базового. Чтобы не пришлось объявлять такие компоненты общедоступными (public), т. е. полностью "раскрывать" их, в языке C++ и введена специальная категория доступности — защищенная (protected). Компоненты, которые имеют такой уровень доступа, заблокированы для всех частей программы, за исключением компонентов самого класса и производного от него.
Осталось только привести сводку правил наследования доступа:
|
Тип наследования доступа |
Доступность в базовом классе |
Доступность компонентов базового класса в производном |
|
public
private |
public protected private public protected private |
public protected private private private недоступны |
По умолчанию установлен тип наследования доступа — private.
Чтобы закончить с вопросом правил наследования доступа, осталось сказать, что в производном классе можно изменять доступность отдельных компонентов базового класса. Например, если в объявление производного класса Subclass из предыдущего примера внести следующее дополнение
class Subclass : BaseClass // private-наследование по умолчанию
{
public:
// Общедоступные компоненты производного класса
BaseClass:rnPublBase; // Конкретно объявляем как public
int nPublSub;
void funcSub();
...
};
то из любого места программы становится возможен доступ к этой компоненте базового класса:
clSub.nPublBase = 7;
Производный класс сам может служить базовым, т. е. от него можно образовывать новые классы. В этом случае полученный класс будет включать в себя элементы всех его базовых классов. От одного базового класса можно образовывать несколько производных. Таким образом, возможна древовидная структура иерархии классов (рис. П1.4).
Схема размещения в памяти объекта простого производного класса представлена на рис. П1.5.
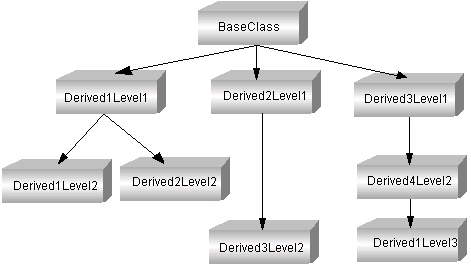
Рис. П 1.4. Древовидная иерархия классов

Рис. П1.5. Схема размещения в памяти объекта простого производного класса
Во всех рассмотренных примерах производный класс образовывался от одного базового класса — так называемое единичное наследование. Однако механизм наследования в C++ более развит и включает наряду с единичным и множественное наследование, при котором производный класс образуется сразу от нескольких базовых, что позволяет создавать достаточно сложные иерархии классов (рис. П1.6):
class Basel
{
// Компоненты первого базового класса
};
class Base2
{
// Компоненты второго базового класса
} ;
class Derived : public Basel, private Base2
(
// Компоненты производного класса
};
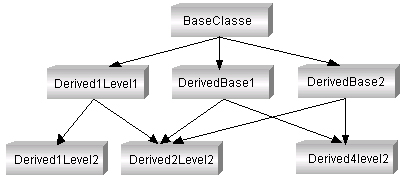
Рис. П1.6. Графовая иерархия классов
В объявлении класса может быть записано любое количество базовых классов, перечисленных через запятую. Порядок перечисления базовых классов произвольный. Он влияет только на последовательность вызова конструкторов, которая является следующей:
1. Сначала вызываются конструкторы всех виртуальных базовых классов; если их несколько, то конструкторы вызываются в порядке их наследования (виртуальные классы мы рассмотрим ниже).
2. Затем вызываются конструкторы невиртуальных базовых классов в порядке их наследования.
3. И, наконец, вызываются конструкторы всех компонентных классов.
Как обычно, последовательность вызова деструкторов является обратной относительно последовательности вызовов конструкторов.
Поскольку множественное наследование является более сложной конструкцией по сравнению с единичным, то вполне очевидно, что при этом возникают и некоторые проблемы.
В случае множественного наследования вполне вероятно, что один и тот же класс может унаследовать несколько объектов с одним и тем же именем:
class Basel
{
int nObj;
// Остальные компоненты первого базового класса
};
class Base2
{
int nObj;
// Остальные компоненты второго базового класса
};
class Derived : public Basel, public Base2
{
// Компоненты производного класса }
}clDer;
В данном случае мы имеем два объекта clDer.nObj с одним и тем же именем, а значит, обращаться к ним просто по имени нельзя. В этом случае выход заключается в использовании оператора разрешения контекста и полных имен объектов:
clDer.BaseClassl::nObj++;
clDer.BaseClass2::nObj++;
Аналогично решается проблема одинаковых имен и при использовании наследования через промежуточный класс:
class BaseClass
{
int nBaseObj;
};
class FirstBaseClass : public BaseClass
{
int nFirstObj;
};
class SecondBaseClass : public BaseClass
{
int nSecondObj;
};
class DerivedClass : public FirstBaseClass, public FirstBaseClass
{
long nDerivedObj;
// Остальные компоненты производного класса
} clDer;
...
clDer.FirstBaseClass::nObj++;
clDer.SecondBaseClass::nObj++;
При наследовании через промежуточный класс возникает другая проблема — при приведении типа указателя одного класса к другому может возникнуть неоднозначность:
DerivedClass clDerived;
DerivedClass *ptrDer = sclDerived;
BaseClass *ptrBase;
ptrBase = (Base *)ptrDer; //Ошибка — неоднозначность приведения типа
Проблема решается выполнением явного приведения типа к классу, для которого неоднозначностей не возникает:
ptrBase = (Base *)(FirstBase *)ptrDer; // Теперь правильно
Размещение объектов производных классов в памяти в случае простого множественного наследования представлено на рис. П1.7.

Рис. П1.7. Размещение объекта в памяти при простом множественном наследовании
Обратите внимание, что если мы передадим Derived* функции, ожидающей Base 1, то все будет в порядке — неоднозначностей не возникает. Однако при вызове функции, ожидающей поступления Base2, возникнет проблема, и необходимо выполнять явное приведение типа.
Давайте теперь посмотрим, что же получается в случае наследования через промежуточный класс. Проблема, которая возникает в этом случае, достаточно наглядно продемонстрирована на рис. П1.8 — это дублирование компонентов "самого" базового класса BaseClass.
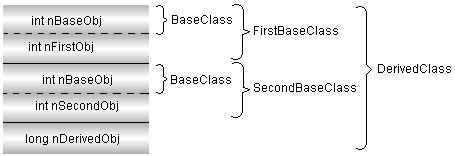
Рис. П1.8. Схема размещения объекта при наследовании через промежуточный класс
Впрочем, некоторые программисты могут и не посчитать это проблемой и сознательно использовать обе (или больше) копии. Однако в большинстве случаев такое положение все-таки нежелательно. Чтобы в таких случаях позволить наследование только одной копии BaseClass, в язык C++ включено ключевое слово virtual, с помощью которого реализуется так называемое виртуальное наследование:
class BaseClass
{
int nBaseObj;
};
class FirstBaseClass : virtual public BaseClass {
int nFirstObj;
};
class SecondBaseClass : virtual public BaseClass {
int nSecondObj;
};
class DerivedClass : public FirstBaseClass, public FirstBaseClass
{
long nDerivedObj;
// Остальные компоненты производного класса
} clDer;
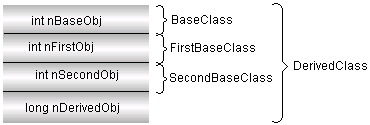
Рис. П1.9. Схема размещения объекта при виртуальном множественном наследовании
Такое дополнение (ключевым словом virtual) изменяет схему размещения объекта производного класса DerivedClass, как это показано на рис. П1.9.
Теперь существует только одна копия BaseClass и нет никакой неоднозначности и избыточности.
Виртуальные функции — полиморфизм
Прямым результатом наследования явилось включение в язык виртуальных функций. Чтобы разобраться, о чем идет речь, рассмотрим пример:
class BaseClass
{
public:
void Method();
};
class DrivedClass : public BaseGlass
{
public:
void Method();
};
void SimpleFunc(BaseClass *ptrBase)
{
ptrBase->Method();
}
А теперь попробуйте ответить на вопрос: "К какому методу Method относится вызов в функции SimpleFunc?" Правильно, к методу базового класса. И для того, чтобы вызвать метод производного класса, необходимо использование операции разрешения контекста.
Что же делать, чтобы иметь возможность вызывать оба метода? Ответ на этот вопрос дает полиморфизм — использование одного и того же вызова для ссылки на разные методы в зависимости от типа объекта. Для поддержки полиморфизма язык программирования должен поддерживать механизм позднего связывания, при котором решение о том, какой именно метод с одним и тем же именем должен быть вызван, принимается в зависимости от типа объекта уже во время выполнения программы.
Обычная практика выбора вызываемого метода на этапе компиляции называется ранним связыванием.
В C++ имеется ключевое слово virtual, использование которого перед именем метода предполагает, что все вызовы этого метода (и всех методов с этим именем в общих производных классах) должны выполняться посредством механизма позднего связывания. Небольшое изменение в предыдущем примере снимает вопрос о неоднозначности вызываемого метода:
class BaseClass.
{
public:
virtual void Method (); // Метод объявлен виртуальным
};
class DrivedClass : public BaseClass
}
public:
void Method();
};
void SimpleFunc(BaseClass *ptrBase)
{
ptrBase->Method();
}
Теперь соответствующий метод будет вызываться в зависимости от того, указатель на какой объект передается в функцию SimpleFunc.
Примечание
• Если метод объявлен виртуальным, он не может быть перегружен.
• Виртуальный метод, чаще называемый "виртуальная функция", не может быть статическим.
В каких же случаях следует использовать виртуальные функции, если учитывать, что механизм позднего связывания требует дополнительных расходов времени на вызов метода? Общее правило следующее: если существует вероятность того, что в некотором производном классе будет использован метод, перекрывающий метод базового класса и которому нужен доступ к компонентам этого базового класса, то он должен быть виртуальным.
Может быть объявлен и виртуальный деструктор, что позволяет использовать механизм позднего связывания при определении того, какой деструктор следует вызывать для удаления объекта.
С виртуальными функциями тесно связано понятие абстрактного класса — такого, который содержит как минимум одну чистую виртуальную функцию. Чистая виртуальная функция — это функция, определенная со спецификатором = 0 и являющаяся такой, для которой нет и не планируется какая-либо реализация. Ее объявление имеет вид:
virtual void Method() =0; // Чистая виртуальная функция
Такие функции должны быть определены в производном классе, иначе и он будет абстрактным.
Абстрактные классы чрезвычайно полезны для организации иерархической структуры классов, когда базовый класс определяет некоторое общее поведение, а некоторые частные особенности переносятся в конкретные производные классы.
Примечание
Нельзя создавать объекты абстрактного класса — он может быть использован только в качестве базового для построения других классов. Однако указатель на абстрактный класс создавать можно.
Так же, как и для функций, язык C++ позволяет переопределить действие большинства операций так, чтобы при использовании с объектами конкретного класса они выполняли заданные действия. Такая перегрузка желательна с точки зрения непротиворечивости использования. Классическим примером, приводимым практически во всех учебниках по C++, является выполнение арифметических операций над классами, представляющими комплексные числа. В C++ механизм перегрузки операций реализован путем определения функции с ключевым словом operator, стоящим перед перегружаемой операцией.
Переопределить операцию для объектов класса можно используя либо соответствующий метод, либо дружественную функцию класса. В случае переопределения операции с помощью метода класса, последний в качестве неявного параметра принимает ключевое слово this, являющееся указателем на данный объект класса. Поэтому если переопределяется бинарная операция, то переопределяющий ее метод класса должен принимать только один параметр, а если унарная, то метод класса вообще не имеет параметров.
Если операция переопределяется при помощи дружественной функции, то она должна принимать соответственно два и один параметр.
При переопределении операций необходимо учитывать некоторые имеющиеся в языке ограничения:
Рассмотрим небольшой класс CPoint из библиотеки классов MFC
class CPoint : public tagPOINT
{
public:
// Constructors
CPoint() ;
CPoint(int initX, int initY);
CPoint (POINT initPt) ;
CPoint(SIZE initSize);
CPoint(DWORD dwPoint);
// Operations
...
BOOL operator==(POINT point) const;
BOOL operator!=(POINT point) const;
void operator+=(POINT point);
void operator-=(POINT point);
// Operators returning CPoint values
CPoint operator-() const;
CPoint operator+(POINT point) const;
...
};
BOOL CPoint::operator+=(POINT point) const
{
return (x += point.x; у += point.у;);
}
Использование перегруженных операторов тривиально:
CPoint ptObjl(l,2);
CPoint ptObj2(3,4) ;
CPoint ptObj3 = ptObjl + ptObj2; // В ptObj3 теперь значение (4, 6)
В заключение рассмотрения перегрузки операций хочется сказать, что при неаккуратном использовании этот механизм может привести к получению очень сложного для восприятия кода. В то же время при правильном написании перегруженные операции могут как резко улучшить читабельность программы, так и повысить вероятность повторного применения существующих алгоритмов.
Метаморфозы, происходящие в мире программирования, просто удивительны. До сих пор мы много говорили о достоинствах инкапсуляции — сведении в единый объект данных и методов для работы с ними. Теперь речь пойдет о шаблонах (templates). Понятие шаблона в C++ обеспечивает то, что
в литературе называют параметризованным типом, и имеет сходство с соответствующими средствами языков Clu и Ada. Одним из основных достоинств шаблона является то, что они позволяют отделить метод от данных (!). Они настолько значительно изменяют внешнюю сторону программирования, что по праву могут считаться одной из самых важных особенностей C++. Они предназначены для создания функций и классов, отличающихся друг от друга только типом обрабатываемых ими данных. Такие функции и классы часто называют соответственно параметризованными или родовыми функциями (generic Junctions) и параметризованными или родовыми классами (generic classes). Для их определения в язык C++ включено ключевое слово template.
Наше знакомство с шаблонами начнем с параметризованных классов. Общий синтаксис объявления шаблона имеет следующий вид:
template<class tType> // Дальше пойдет шаблон
class className
{
// Компоненты класса
};
Здесь префикс template<class tType> говорит о том, что описывается параметризованный класс, имеющий параметром тип шаблона tType. При необходимости можно определить несколько параметризованных типов данных, разделяя их запятой. В пределах определения класса имя tType можно использовать в любом месте.
После того как параметризованный класс объявлен, можно создавать его конкретную реализацию:
className<dataType> clObj;
Тип данных, который заменяет собой переменную tType и с которыми фактически оперирует класс, задается параметром dataType, например
className<float *> clObj;
В результате такого определения на этапе компиляции на основании заданного типа будет автоматически сгенерирован соответствующий объект. Таким образом, использование шаблонов не влечет за собой никаких дополнительных временных издержек по сравнению с явно задаваемыми типами.
Методы параметризованного класса являются параметризованными функциями, и когда они определяются вне базового класса, параметр типа шаб- • лона должен быть указан явно, например:
template<class tType> void className<tType>::memberFunc()
{
// Тело функции
}
Замечательно здесь то, что за формирование версии каждой параметризованной функции для каждого типа аргумента отвечает компилятор, а не программист.
Можно определить параметризованные функции, не являющиеся методами какого-либо класса. Общий синтаксис такого объявления имеет вид:
template<class tType> retType funcName(parametrList);
Во всем остальном такие функции ничем не отличаются от обычных.
При рассмотрении шаблонов используются и другие термины, которые можно встретить в литературе по C++. Конкретную версию функции, создаваемую компилятором, называют порожденной функцией (generated function). Процесс построения такой функции называется конкретизацией (instantiating).
Ранее мы рассматривали различные структуры данных. При этом каждая из них использовала единственный конкретный тип данных, с которым она могла работать. Теперь, после знакомства с шаблонами C++, легко создать классы контейнеров, которые будут работать с широким кругом типов данных — как встроенных в язык, так и создаваемых программистом. Большую пользу в этом процессе оказывает библиотека MFC, в которую входят специальные классы для хранения групп объектов:
Их использование исключает необходимость в самостоятельной разработке и длительной отладке, что позволяет уделить больше времени прикладной части приложения.
Для тех, кто заинтересовался шаблонами, могу порекомендовать прекрасную книгу Герберта Шилдта "Теория и практика C++".
Обработка исключений обеспечивает передачу управления и информации в произвольную точку вызова, где была затребована обработка исключения данного типа. Могут возникать и обрабатываться исключения любого типа.
Средства обработки исключений нужны, чтобы дать возможность программе, где возникает исключение, которое она не может обработать, передать эту обработку некоторой другой программе, из которой данная программа явно или неявно была вызвана.
Описываемая ниже модель обработки исключений предназначена главным образом для обработки ошибок. Другие варианты ее использования, такие
как завершение цикла или дополнительные пути "нормального" завершения функций, хотя и возможны, однако считаются второстепенными.
Реализации обработки исключений полагаются редкими по сравнению с реализацией функций, а возникновение исключений — возникающими редко по сравнению с вызовами функций. Цель обработки исключений — создание программ вне устойчивых к сбоям подсистем без необходимости обращать внимание на обработку исключений в каждой функции. Другими словами, во многих случаях нет необходимости делать каждую функцию устойчивой к сбоям. Гораздо проще (и лучше), чтобы лишь некоторые функции были ответственны за обработку всех ошибок, возникающих в них и в вызываемых ими функциях.
Язык C++ сам обеспечивает обработку исключений (exception handling), причем исключений явных, т. е. таких, возможное возникновение которых должен предусмотреть сам разработчик. При этом проверка необходимости обработки и возбуждение исключения сохраняются, т. е. сохраняется проверка возникновения ошибок, а сама обработка производится в другом месте. Обработка исключений языка C++ является обработкой с завершением, т. е. у обработчика нет возможности возобновить исполнение с точки возникновения исключения. При возникновении исключения в обработчик передается произвольное количество информации с контролем типов.
Для лучшего понимания того, как на практике реализуется обработка исключений, приведем следующую синтаксическую сводку:
блок-с-контролем:
try составной_оператор список_обработчиков
список_обработчиков:
обработчик список_обработчиковОрt
обработчик:
catch (объявление_исключения) составной_оператор
объявление_исключения:
список_спецификаторов_типа описатель
список_спецификаторов_типа абстрактный_описатель
список_спецификаторов_типа
...
выражение_возбуждения_исключения:
throw выражениев орt
Хотя приведенная сводка вполне прозрачна для понимания, дадим краткий комментарий. <составной_оператор> после ключевого слова try содержит последовательность операторов, включая вызовы функций, которые проверяются на возникновение исключения. Такой блок еще называют защищенный блок (guarded block). По сути, именно в рамках этого составного оператора может встретиться <выражение_возбуждения_исключения>, где необязательное <выражение> после ключевого слова throw как раз и определяет тип и информацию, описывающую само исключение.
Примечание
Возбуждение исключения может происходить и как бы вне составного оператора, следующего после ключевого слова try, т. к. отсутствие в функции этого составного оператора еще не значит, что данная функция не выполняется в некотором блоке с контролем, который может быть определен и в библиотеке, что исключает его явное наличие в написанном разработчиком коде программы.
Ключевое слово throw без последующего <выражения> может использоваться только в обработчиках исключений для организации обработки текущего исключения в следующем по иерархии вызова блоке с контролем. Заключенное в круглые скобки <объявление__исключения> после ключевого слова catch определяет тип данных, описывающих обрабатываемое исключение. Причем тип данных может быть любым допустимым в языке типом, включая класс. Если в качестве <объявление_исключения> используется многоточие (...), обработчик берет на себя обработку исключений любого типа и, что очень важно, в том числе обработку структурных исключений. Последняя возможность облегчает совместное использование обоих видов обработки исключений. Такой обработчик должен быть последним в списке обработчиков своего блока с контролем.
Обработчики исключения выполняются только при возникновении исключения, заданного типом <объявление_исключения>, и если это исключение не было обработано ранее (об этом ниже). Если же исключения нет, код обработчика не выполняется. Запрещен также переход в обработчик с использованием оператора goto или метки case оператора switch. Однако такой запрет компилятором может не контролироваться, в частности, Microsoft Visual C++ 6.0 этого не делает. Приложение, использующее такой метод выполнения, просто будет аварийно завершено.
Сразу после выполнения оператора throw весь код до того места в программе, где будет обрабатываться исключение, игнорируется, т. е. он выполняться не будет. Это один из ключевых принципов, на которых базируется вся обработка исключений, и о нем всегда необходимо помнить при разработке устойчивых к сбоям программ.
Несколько слов следует сказать о том, что же такое блок с контролем. Обычно термин "блок" используется для указания на последовательность операторов, заключенную в фигурные скобки. Напротив, блок с контролем представляет собой составной оператор, следующий за ключевым словом try, и список обработчиков. Причем между составным оператором и списком обработчиков не должно быть ни одного другого оператора. Вот простейший пример.
int x;
...
try
{
if (x < 0)
throw 0;
else if (x > MAX_VALUE)
throw "Out of scope";
}
catch (int)
{
...
}
catch (char *error_message)
{
puts(error_message);
throw; // Передаем обработку во внешний блок_с_контролем,
// который в данном примере не представлен
}
catch (...) //В данном примере этот код
{ // никогда не будет выполняться, т. к. реализованы
... // все необходимые типизированные обработчики
}
В заключение этого раздела осталось пояснить происхождение всех трех ключевых слов, используемых в синтаксисе обработки исключения. Первое слово try (проба, испытание) у разработчиков не вызывало сомнений — его значение как нельзя лучше обозначает соответствующие действия. Слово catch (перехватывать) вполне подходит, однако мы все время говорим об обработке (handle), нежели о перехвате. Термин handle был признан нецелесообразным из-за его частого использования в программах для IBM-совместимых персональных компьютеров и компьютеров Macintosh. При переходе на C++ не раз приходилось менять имена переменным, таким как new, из-за того, что это слово является ключевым в языке. Термин throw (бросать) был использован вместо терминов signal или raise, т. к. стандартная С-биб-лиотека уже имеет функции с этими именами.
Основное достоинство обработки исключений заключается не только в том, что она дает возможность обрабатывать самые различные ситуаций, которые могут возникать в программе. Сам механизм обработки, основанный на свертывании стека, без которого просто невозможна правильная передача управления, обеспечивает корректное уничтожение переменных и объектов, для которых была зарезервирована память и другие ресурсы. Более того, именно язык программирования C++ в полной мере обеспечивает такое корректное уничтожение. Достигается это путем автоматического вызова деструкторов в процессе свертывания стека для всех объектов, созданных до возбуждения исключения.
При возникновении исключения управление передается на ближайший обработчик соответствующего типа, причем ближайшим является тот, в чей блок с контролем исполнение попало в последнюю очередь. Если в этом блоке обработчик не найден, проверке подвергается следующий по иерархии вызова блок с контролем. Такой поиск осуществляется до тех пор, пока не будет найден подходящий обработчик.
Естественно, что может возникнуть ситуация, когда соответствующий обработчик так и не будет найден, т. к. он попросту отсутствует. Что же происходит в этом случае, и является ли это ошибкой? Ответ на первый вопрос таков: до того, как обработчик получает управление, на этапе свертки стека возбуждается еще одно исключение и вызывается функция terminate. Считать ли такую ситуацию ошибочной, зависит от того, какого рода исключение возникло. Если все равно приложение должно быть завершено, т. к. дальнейшее выполнение невозможно, то именно такое завершение вполне можно считать оправданным. Если же разработчик не позаботился о соответствующей обработке, то естественно это будет ошибкой, причем скорее всего логической.
Как только приложение определилось с реакцией на исключение (обработка или завершение), но непосредственно перед тем, как эта реакция получает управление, происходит свертка стека. Во-первых, для всех объектов, расположенных в нем и имеющих деструкторы, последние вызываются. Если объект был построен частично, то деструкторы вызываются только для его полностью построенных подобъектов. Если исключение возникло в конструкторе на элементе автоматического массива — разрушаться будут лишь уже построенные элементы этого массива. Во-вторых, освобождается и сам стек. Обязательный вызов деструкторов позволяет при возникновении исключений не только корректно уничтожать объекты, но и выполнять другие необходимые действия, например, освобождение ресурсов, закрытие файлов и т. п.
Для лучшего понимания того, как определяется блок с контролем, а также соответствующий обработчик исключения, приведем три возможных варианта.
void inner(}
{
throw 0; // Исключение в блоке_с_контролем,
// определенным в функции outer
}
void outer(),
{
try
{
inner() ;
} catch (int) // Обработчик исключения,
// возбуждаемого в функции inner
{
}
}
Наличие в функции inner возбуждения исключения может привести к тому, что оно не будет иметь обработчика, т. к. при использовании этой функции в разных контекстах может случиться так, что программист просто забудет предоставить в каждом случае соответствующий обработчик. Для того чтобы как-то проконтролировать возникновение таких ситуаций, можно либо переопределить функцию завершения (terminate), либо в функции, находящейся на самом верху иерархии вызовов, например, main, определить блок с контролем, содержащим обработчик, способный обрабатывать исключения любого типа (catch (...)).
Следующий пример иллюстрирует вариант вложенных блоков с контролем. Наличие блока с контролем в функции inner не очевидно для функции outer.
void inner(int mode)
{
// Оба исключения возбуждаются в текущем блоке с контролем,
// однако их обработчики определены в различных блоках (и функциях)
try
{
if (mode != 0)
throw "Exception!";
else
throw 0;
}
catch (char *) // Обработчик исключения,
// возбуждаемого в этой же функции
{
}
}
void outer()
{
try
{
inner(0) ;
}
catch (int) // Обработчик исключения,
// возбуждаемого в функции inner
{
}
}
Последний пример иллюстрирует вложенные блоки с контролем, реализованные в одной функции.
void outer(int mode)
{
try
{
try
{
if (mode != 0)
throw "Exception!";
else
throw 0;
}
catch (char *)
{
}
}
catch (int)
{
}
}
Свертка стека никак не сказывается на объекте, определяющем тип исключения. Достигается это тем, что обработчик получает не сам объект, а его копию, которая реализуется, возможно, с помощью конструктора копирования, при этом осуществляется копирование объекта из одного места стека в другое.
try
{
CExClass e_try("Exception", 15);
throw e;
}
catch (CExClasss e_exept) // Ошибки не будет — ссылка e_exept
{ // ссылается не на объект e_try
}
Так как операнд throw трактуется в точности так же, как параметр в вызове функции или операнд в операторе return, а уничтожение самого операнда происходит после соответствующего копирования, обработчик исключения получает объект (копию), который располагается в текущем для обработчика месте стека. Интересно, что объекты, описывающие исключения, реализованные в библиотеке MFC, создаются не в стеке, как в предыдущем примере, а в свободной памяти. Естественно, что в этом случае требуется явное удаление таких объектов.
try
{
CException *e = new CException;
throw e;
}
catch (CException *e)
{
delete e;
}
Такой подход не годится для обработки исключений, возникающих в процессе управления свободной памятью, т. к. в этих ситуациях некорректно использовать для размещения временного объекта обычные средства размещения в свободной памяти — ее и так уже возможно не хватает. Кроме того, подключение общего механизма работы со свободной памятью было бы неэффективным и сделало бы обработку исключений чувствительной к ошибкам работы со свободной памятью. Таким образом, реализация может использовать заранее выделенный пул памяти исключительно для механизма обработки исключений. Что касается последнего момента, то для исключений, связанных с отсутствием свободной памяти, библиотека MFC обращается к заранее созданным объектам, описывающим такого рода исключения.
Следующий пример демонстрирует порядок вызовов деструкторов для различных объектов. Для демонстрации порядка вызова деструктора во время сворачивания стека используются два класса: CExcept, который является классом описания исключения, и CTheObject.
linclude "afxwin.h"
class CTheObject
{
public:
CTheObject ();
-CTheObjectO ;
};
class CExcept
{
public:
CExcept();
CExcept(CExcept& e) ;
~CExcept() ;
};
CTheOb j ect: : CTheOb j ect ()
{
TRACE("\tConstruct: CTheObject\n");
}
CTheObject::-CTheObject()
{
TRACE("\tDestruct: CTheObject\n");
}
CExcept::CExcept()
{
TRACE ("\tConstruct: CExceptW) ;
}
CExcept::CExcept(CExcept&)
{
TRACE ("\tCopy Construct: CExceptW) ;
}
CExcept::-CExcept ()
{
TRACE ("\tDestruct: CExceptW) ;
}
void ThrowFunction()
{
TRACE ("Start »» ThrowFunction\n) ;
CTheObject o;
CExcept e;
throw e;
TRACE ("End »» ThrowFunctionW) ;
}
int WINAPI WinMain(
HINSTANCE hlnstance,
HINSTANCE hPrevInstance,
LPSTR IpCmdLine,
int nCmdShow)
{
TRACE ("Start »» MainXn");
try
{
TRACE("Begin -> try\n");
ThrowFunction();
TRACE("End -> try\n");
}
catch (CExceptS e)
{
TRACE("Begin -> catch\n");
TRACE("End -> catch\n");
}
TRACE ("End »» MainW);
return 0;
}
Ниже приведено содержимое окна отладчика (номера строк и отступы добавлены для облегчения понимания):
1. Start »» Main
2. Begin -> try
3. Start »» ThrowFunction
4. Construct: CTheObject
5. Construct: CExcept
6. Copy Construct: CExcept
7. Destruct: CExcept
8. Destruct: CTheObject
9. Begin -> catch
10. End -> catch
11. Destruct: CExcept
12. End »» Main
Как видите, результат согласуется с изложенным ранее материалом. Обратите внимание на то, что сворачивание стека начинается только после того, как завершается создание копии объекта описания исключения. Пожалуй, стоит также обратить внимание на то, что копия объекта класса CExcept уничтожается сразу по выходу из обработчика исключения. Кстати, при замене типа обработчика со ссылки на копию объекта (вместо ссылки — catch (CExcept е)) строки 6 и 11 будут продублированы, т. к. в этом случае объект описания должен создаваться (и уничтожаться) дважды: при создании копии и при создании фактического параметра.
В связи с тем, что язык C++ позволяет обрабатывать исключения любого типа, следует определить обработчики для каждого типа исключения. Либо обработчик может обрабатывать исключения того же типа, что объект описания, использованный при возбуждении ситуации, либо исключение может быть обработано обработчиком любых исключений. Кроме того, возможно использование ссылок в качестве указания типа обрабатываемого исключения. Учтите, что использование ссылок сокращает количество создаваемых копий при передаче объекта описания исключения в обработчик.
Для исключений, описанных при помощи классов, так же может быть использован обработчик базового класса объекта описания исключения. Наконец, вполне возможно использование указателей на объекты описания исключений. Однако в этом случае указание на объект, находящийся в стеке, приведет к тому, что обработчик получит указатель на уже уничтоженный объект, т. к. к моменту передачи управления обработчику сворачивание стека уже завершено.
Приведу сводку возможных обработчиков для всех указанных выше типов исключений. После возбуждения исключения оно может быть обработано следующими обработчиками:
Комитет по разработке стандарта языка программирования C++ предполагает обработку двух групп ситуаций, которые могут возникнуть при возбуждении и обработке исключений.
Первая включает ситуацию, когда в функции со спецификацией исключений возбуждается исключение, не указанное в спецификации.
Вторая группа включает целый набор ситуаций, когда:
Рассмотрим эти группы по порядку.
При возникновении исключения, не указанного в спецификации исключений функции, механизм обработки исключений вызывает системную функцию unexpected, которая в соответствии с рекомендациями ANSI может быть заменена на пользовательскую функцию при помощи функции set_unexpected. Однако Microsoft Visual C++ 6.0 не поддерживает спецификацию исключений при описании функций (подробнее см. документацию по C++), и, соответственно, пользовательская функция вызываться никогда не будет.
Примечание
В ряде случаев стандарт языка программирования накладывает определенные требования на реализацию тех или иных положений. Однако часто некоторые моменты зависят именно от реализации. Например, размещение (выравнивание) полей структур и в С, и в C++ зависит от реализации. С другой стороны, конкретный компилятор может отходить от стандартов как в сторону расширения, так и в сторону усечения тех или иных возможностей. Именно поэтому принято говорить не просто о компиляторе языка C++, а, например, о Microsoft Visual C++, Borland C++, Symantec C++ и т. п. Более того, хорошо еще добавлять номер версии.
Это вполне оправдано, т. к. даже разработчики стандарта указывают, что:
"В идеале могут возникнуть только исключения, упомянутые в спецификации исключений... Почему бы не достичь идеала, заставив каждую функцию иметь спецификацию исключений и отвергать любую программу, где возникнет неожиданное исключение? Предотвращение подобных ошибок во время компиляции легло бы тяжким бременем на программиста, а потому он стал бы обходить и обманывать контроль... Кроме того, если функция изменилась и возбуждает новое для нее исключение, все функции, прямо или косвенно вызывающие ее, должны быть изменены и перекомпилированы".
Возникновение одной из ситуаций второй группы приводит к вызову функции terminate, которая может быть заменена на пользовательскую при помощи функции set_terrainate. Функция terminate просто вызывает функцию abort системной библиотеки. Пользовательская же функция может выполнить какие-либо необходимые действия. Вообще по завершению выполнения таких действий рекомендуется вызвать функцию exit для завершения текущего потока, т. к. в отличие от функции abort функция exit все-таки производит некоторые полезные действия, например, закрывает открытые файлы. Однако, если этого не сделать, по завершению пользовательской функции будет в обязательном порядке вызвана функция abort, т. к. никаких попыток возобновить или продолжить работу не делается.
Функция set_terminate возвращает указатель на последнюю установленную функцию завершения, причем для каждого потока определяется своя функция завершения. Это может быть полезно, но следует помнить, что, заменив функцию завершения в одном потоке, не следует ожидать той же реакции и для другого потока.
В общем случае для того, чтобы избежать возникновения ситуации отсутствия обработчика исключения, следует просто добавить обработчик всех исключений в конец списка обработчиков.
Обработчики исключений проверяются на применимость в порядке появления в списке обработчиков. Ошибкой является расположение обработчика исключения базового класса перед обработчиком производного от него класса, поскольку при таком порядке обработчик на производный класс никогда не получит управления. То же самое касается и обработчика всех исключений (catch (...)). Он должен быть последним в списке, иначе ни один обработчик, указанный после него, также не получит управления. Интересно, что преобразование типов, например, от int к float, не производится, так что следующий код приведет к возникновению ситуации по отсутствию обработчика:
try
{
throw 25;
}
catch (float)
{
}
Альтернативным подходом к обработке исключений, описываемых при помощи объектов классов, может быть использование механизма виртуальных функций:
class CError
{
...
virtual Evaluate();
}
class CMathError : public CError
{
...
virtual Evaluate();
};
class CDataError : public CError
{
...
virtual Evaluate();
} ;
try
{
...
}
catch (CErrorS e)
{
e.Evaluate();
}
Тип обработчика должен быть ссылкой, иначе в обработчик будет передана только часть объекта (в данном примере относящаяся к классу CError). Если же тип обработчика является указателем, то объект должен быть статическим или располагаться в свободной памяти, и его необходимо будет после использования удалить.
Способ обработки исключений можно разделить на две группы. К первой относятся случаи, когда код возбуждения исключения находится в той же функции, что и обработчик. Ко второй — когда в try-блоке происходит вызов некоторой функции, в которой и происходит возбуждение исключения. Два этих случая требуют различного подхода к управлению объектами, создаваемыми с момента входа в защищенный блок и до возбуждения исключения. Конечно, речь идет прежде всего об объектах, динамически создаваемых в свободной памяти, а также о действиях над ресурсами, которые следует выполнить по завершению работы, например, закрыть открытые файлы.
В первом случае рекомендуется инициализировать переменные значениями, характеризующими начальное состояние. Лучше всего на эту роль подходит значение NULL. По завершению обработки исключения все объекты, указатели на которые не равны NULL, должны быть освобождены. Такой подход существенно упрощает программирование, избавляя код от громоздких конструкций:
void Function()
{
LPVOID IpBuffer =NULL;
FILE *fp_l = NULL, *fp_2 = NULL;
try
{
IpBuffer = mailoc(l000);
if {IpBuffer}
throw "Нет памятиХп";
if «fp_l = fopen("FILE_1.DAT", "r")) == NULL)
throw "Невозможно открыть файл FILE_1.DAT\n";
if «fp_2 = fopen("FILE_2.DAT", "w")} == NULL)
throw "Невозможно открыть файл FILE__2. DAT\n";
if (!fread(IpBuffer, I, 1000, fp_l))
throw "Ошибка чтения из файла FILE_1.DAT\n";
if (Ifwrite(IpBuffer, 1, 1000, fp_2))
'throw "Ошибка записи в файл FILE_2.DAT\n";
}
catch (char *error)
{
puts(error);
}
if fIpBuffer != NULL)
free(IpBuffer);
if (fp_l != NULL)
fclose(fp_l);
if (fp_2 != NULL)
fclose(fp_2);
}
Все деинициализирующие действия выполняются в одном месте. В противном случае, начиная с ошибки открытия первого же файла, потребовалось бы перед каждым возбуждением исключения производить все больше и больше такого рода действий — сначала освобождение памяти, далее освобождение памяти и закрытие первого файла, освобождение памяти, закрытие первого файла и закрытие второго файла и т. д. Кроме того, после выполнения обработчика все равно бы потребовалось определить, какие из деинициализирующих действий выполнены, а какие нет. (Альтернативой последнему может служить завершение функции в конце обработчика.)
К сожалению, в случае, когда возбуждение исключения и обработчик находятся в различных функциях, перед собственно возбуждением исключения потребуется освобождение локальных ресурсов этой функции. Тут уже ничего не поделаешь. Кстати, частным случаем является возбуждение исключения в конструкторе класса, что часто применяется в классах библиотеки MFC, например, классах графических ресурсов.
Вообще при невозможности правильного создания объекта класса, когда память под него уже выделена, но дополнительная инициализация завершается неудачно, не существует простого способа удаления самого объекта во время выполнения конструктора. Чтобы как-то сигнализировать о неудач-
ном выполнении конструктора, можно предусмотреть специальный член класса, либо воспользоваться механизмом исключений. Однако наиболее приемлемый способ — создать "пустой" конструктор и инициализирующую функцию (например, Create), неудача выполнения которой потребует простого вызова деструктора напрямую, вне каких-либо методов, включая конструктор.
Примечание
Тому, кто хочет более подробно познакомиться с обработкой исключений, могу порекомендовать книгу А. Мешкова и Ю. Тихомирова "Visual C++ и MFC. Том II".