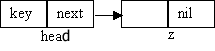Ссылки и указатели. Линейные и циклические
списки
Цель: изучение фундаментальной абстрактной
структуры - связных списков.
На сегодняшнем занятии мы рассмотрим
фундаментальную абстрактную структуру
связанный список.
Связанный список - это набор последовательно
организованных данных.
Связные списки определены как примитивы в
некоторых языках программирования (в частности в
Лиспе, Delphi), но не в Паскале. Однако Паскаль
предоставляет некоторые базовые примитивные
операции позволяющие легко использовать
связанные списки.
Главное преимущество связанных списков перед
массивами состоит в том, что они могут уменьшать
или увеличивать свои размеры во время выполнения
программы. В частности, мы не должны заранее
знать его максимальный размер.
Второе преимущество состоит в том, что они
обеспечивают гибкость при переорганизации их
элементов. Такая гибкость получается за счет
потери в скорости доступа к произвольному
элементу списка. Это станет более очевидным ниже,
после того, как мы ознакомимся с некоторыми
основными свойствами связанных списков и
базовыми операциями определенными над ними.
Список можно представить в виде звеньев цепи.
В массиве последовательная
организация обеспечивается непосредственно (согласно
индексу).
Для связанного списка используется
специальный способ организации данных, согласно
которому его элемент содержится в "узле"
содержащем данные, а также "ссылку" на
следующий "узел".
Узел и ссылку можно описать так:
Type
Link = ^Node;
Node = record
Data: integer;
Next: Link;
End;
Для описания списка мы будем использовать
дополнительно два вспомогательных узла head и z.
Узел head будет указывать на первый элемент списка,
а z - последний элемент списка. Head иногда называют
"голова" списка, а z - "хвост".
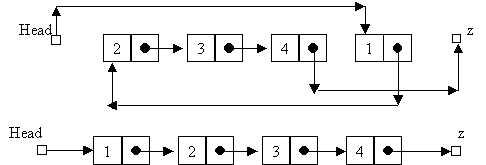
Тогда список можно будет представить в
следующем виде.
Такое представление данных позволяет
производить некоторые операции гораздо более
эффективными методами, чем над массивами.
Например, если мы хотим передвинуть элемент 1 из
конца в начало, то для произведения такой
операции в массиве нам потребовалось бы
передвинуть все его элементы чтобы освободить
место. В связанном же списке мы только меняем
ссылки. Оба варианта рисунка эквивалентны; они
только по разному нарисованы. Мы просто
переустанавливаем ссылку узла, содержащего 1, на
узел содержащий 2, а ссылку пустого узла head на
узел содержащий 1. Даже если бы список был очень
большой, то нам все равно потребовалось бы только
три перестановки ссылок для подобного обмена.
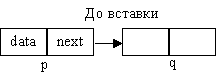
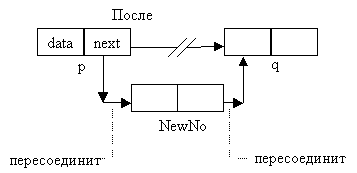
Что более важно, теперь мы можем
говорить о "вставке" элемента в связанный
список (что увеличивает его длину на один элемент)
- операции которая столь неестественна и
неудобна на массивах. На рисунке показано как
вставить в список новый узел. Нужно вначале
добавить этот узел, затем создать ссылку на узел
q, а затем изменить ссылку узла p на новый узел. Для
этого требуется изменить лишь две ссылки в
независимости от длины списка.
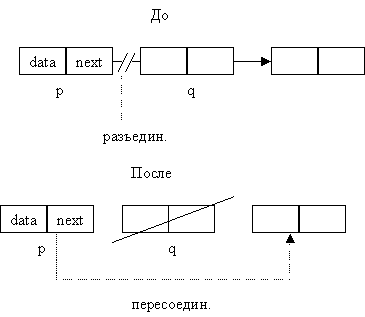
Аналогично, мы можем вести речь об "удалении"
элемента из списка (что уменьшает его размер на
один элемент). Нужно просто переставить ссылку на
узел, который следует за узлом q и после этого
узел содержащий q должен быть уничтожен.
С другой стороны, есть и операции для
которых связанный список не очень хорошо
подходит. Наиболее очевидная из них - это "найти
k-й элемент" (найти элемент по его индексу): в
массиве это делалось простым обращением типа a[k],
но в связанном списке мы должны пройти по k
ссылкам.
Другой неестественной операцией над
связанными списками является операция "найти
элемент перед заданным". Если все, что у на есть
- это ссылка на элемент q в нашем примере, то
единственный способ найти элемент p, который
указывает на q - это пройти по всем ссылкам
начиная с узла head. На самом деле - эта операция
необходима для удаления заданного элемента из
списка: как же иначе мы можем переустановить
ссылку предыдущего узла ? Во многих задачах, мы
можем обойти эту проблему посредством изменения
формулировки этой фундаментальной операции на
"удалить узел следующий после данного".
Аналогичная проблема может быть обойдена и для
вставки посредством изменения определения
операции на "вставить элемент после заданного
узла".
Паскаль предоставляет нам некоторые
примитивные операции которые позволяют нам
непосредственно создавать связанные списки.
Следующий фрагмент кода - это пример реализации
основных функций, которые мы только что
обсуждали.
Type
Link = ^Node;
Node = record
Data: integer;
Next: Link;
End;
Var
Head, z: link;
procedure list_initialize;
begin
new( head );
new( z );
head^.next := z;
z^.next := nil;
end;
procedure insert_after( v : integer; t : link );
var
x : link;
begin
new(x);
x^.data := v;
x^.next := t^.next;
t^.next := x;
end;
procedure delete_next( t : link );
var
del: link;
begin
del := t^.next;
t^.next := t^.next^.next;
dispose(del);
end;
Давайте рассмотрим их по подробнее.
Link = ^Node; - здесь создается новый тип Link,
который является типизированным указателем на
тип Node. Тип Node представлен ниже.
Указатель - это переменная целого типа, которая
интерпретируется как адрес байта памяти,
содержащий некоторый элемент данных.
Давайте поподробней разберем это определение.
Память компьютера можно представить в
следующем виде. Она разбита на блоки каждый такой
блок называется сегментом. В Dos номер каждого
сегмента может содержать максимум 16 бит(число
$FFFF, когда все биты равны
1)(символ $ - это знак шестнадцатеричной
системы исчисления) , т.е. любой сегмент может
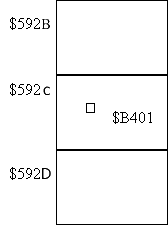
иметь номер [0; $FFFF]. Предположим, что мы
рассматриваем участок памяти с сегментами $592B,
$592C, $592D. Чтобы найти конкретную ячейку памяти
внутри каждого сегмента есть так называемое
смещение, которое тоже может иметь номер [0; $FFFF]. К
примеру пусть смещение внутри сегмента $592C будет
$B401, тогда указатель на эту ячейку памяти будет
иметь значение $592CB401.
procedure list_initialize;
new( head ); - процедура new создает новую
динамическую переменную типа node и устанавливает
значение переменной head таким образом, чтобы оно
указывало на эту новую динамическую переменную,
т.е. программа ищет в памяти свободный участок
длиной 6($6) байт(запись node имеет два типа integer(2
байта) и pointer(4 байта)). Как только она его находит
она резервирует этот участок, т.е. объявляет этот
участок памяти занятым и другие переменные уже
не могут размещать там информацию. Затем
программа присваивает переменной head адрес этого
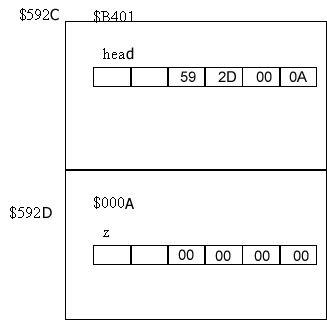
свободного участка. Пусть программа нашла
свободный участок памяти начиная с адреса $592CB401 и
присвоила этот номер переменной head.
new( z ) - пусть программа нашла участок
памяти со следующим адресом $592D000A и присвоила его
z.
Как же происходит обращение к содержимому
адреса памяти? С помощью оператора ^. К примеру,
head^.key:=10; Что здесь происходит? Мы заносим в
содержимое ячейки $592CB401, а конкретней в первые 2
байта (т.к. тип integer занимает 2 байта) в область
называемую key - число 10.
head^.next := z; - здесь мы заносим в ячейку
$592CB401, начиная с 3 байта(т.к. первые два заняты key) в
область называемую Next число $592D000A.
z^.next := nil - ячейку памяти адресуемую z, а
конкретней область next заполняем нулями.
procedure insert_after( v : integer; t : link );
procedure delete_next( t : link );{аналогично и см.
рис.}
Почему использование пустых узлов столь
полезно?
Во-первых, если бы мы условились держать
указатель на начало списка вместо того, чтобы
держать узел head, то процедуре вставки
потребовалась бы специальная проверка для
вставки в начало списка.
Во-вторых, соглашение о пустом узле z
предохраняет процедуру удаления от излишней
проверки на удаление из пустого списка.
А эти проверки существенно сказываются на
времени работы программы.
Выражение типа head^.next^.key дает нам
первый элемент списка, а head^. Next^.next^.key -
второй.
Давайте создадим программу обрабатывающею
информацию об автомобилях.
program car;
uses
crt;
type
namestr = string[20];
Link = ^Node;
Node = record
name: namestr;
speed: integer;
next: link;
end;
var
head, z: link;
namfind: namestr;
v: 0..4;
endmenu: boolean;
procedure list_initialize;
begin
new(head);
new(z);
head^.next:=z;
z^.next:=nil;
end;
procedure list_destroy;
begin
dispose(head);
dispose(z);
end;
procedure insert_after(name1: namestr; speed1: integer; t: link);
var
x : link;
begin
new(x);
x^.name := name1;
x^.speed:= speed1;
x^.next := t^.next;
t^.next := x;
end;
procedure delete_next(t: link);
var
del: link;
begin
del := t^.next;
t^.next := t^.next^.next;
dispose(del);
end;
procedure InpAuto;
var
nam: namestr;
sp: integer;
begin
write('Введите марку автомобиля: ');
readln(nam);
write('Максимальная скорость: ');
readln(sp);
insert_after(nam, sp, head);
end;
procedure Mylist;
var
Curr: Link;
begin
Curr:=head^.next;
While Curr^.next <> nil do
begin
writeln('Марка: ', Curr^.name, ' Скорость: ', Curr^.Speed);
curr:=curr^.next;
end;
write('Вывод списка окончен нажмите Enter.');
readln;
end;
function findname(fn: namestr): link;
var
Curr: Link;
begin
Curr:=head;
While Curr<>Nil do
if Curr^.name=fn then
begin
findname:=curr;
exit;
end
else
curr:=curr^.next;
findName:=Nil;
end;
begin
list_initialize;
endmenu:=false;
repeat
clrscr;
writeln('Укажите вид работы:');
writeln('1. Запись первым в список');
writeln('2. Удаление первого объекта из списка');
writeln('3. Просмотр всего списка');
writeln('4. Удаление объекта, следующего в списке за
указанным');
writeln('0. Окончание работы');
readln(v);
case v of
1: inpauto;
2: delete_next(head);
3: mylist;
4: begin
writeln('Введите марку автомобиля, за которым
следует удаляемый из списка');
readln(NamFind);
delete_next(FindName(namfind));
end;
else
endmenu:=true;
end;
until endmenu;
list_destroy;
end.
end;
Следующий вид списков - это циклические списки.
Циклический список - это список последний
элемент, которого указывает на первый. Этот
список позволяет программе снова и снова
просматривать список по кругу до тех пор, пока в
этом есть необходимость.
В качестве примера, мы рассмотрим так
называемую "проблему Джозефа". Она состоит в
следующем: представьте себе, что N человек решили
совершить массовое самоубийство, выстраивая
себя в круг и убивая каждого М-го человека и
постепенно сужая круг. Надо найти человека,
который умрет последним (хотя возможно под конец
он изменит свое мнение по этому вопросу), или, по-другому,
найти порядок смерти этих людей. Например, если N=9
и М=5, то люди будут убиты в следующем порядке: 5 1 7 4
3 6 9 2 8. Данная программа читает значения N и M, и
затем распечатывает этот порядок.
Эта программа использует циклический
связанный список для прямого симулирования
порядка совершения самоубийств. Сперва
создается список с ключами от 1 до N: переменная head
указывает на начало списка в процессе его
создания, а затем программа делает чтобы
последний элемент в списке указывал на head. Затем
программа проходит по этому циклическому списку,
пропуская M-1 элементом и уничтожая следующий
после них узел до тех пор, пока в списке не
останется один единственный элемент (который
указывает на себя самого).
Program Josef;
Type link=^node;
node=record
data:word;
next:link;
end;
Var N,M:word;
head:link;
Procedure Init;
Var q,l:link;
i:word;
Begin
Write('Enter N: ');
Readln(N);
New(head);
l:=head;
Head^.data:=1;
Head^.next:=head;
For i:=2 to n do
begin
New(q);
q^.data:=i;
l^.next:=q;
q^.next:=head;
l:=q;
end;
End;
Procedure Del;
Var i,k:word;
q,p:link;
Begin
Write('Enter M: ');
Readln(M);
k:=0;
i:=1;
q:=head;
While k<n-1 do
begin
While i<m-1 do
begin
inc(i);
q:=q^.next;
end;
i:=0;
inc(k);
p:=q^.next;
q^.next:=q^.next^.next;
writeln(p^.data:4);
dispose(p);
end;
Writeln('The Last: ',q^.data);
End;
Begin
Init;
Del;
readln
End.
Итак, на сегодняшнем занятии мы рассмотрели
ссылки и указатели, линейные и циклические
списки. |