Оценка программ
Для большинства проблем существует много
различных алгоритмов. Какой из них выбрать для
решения конкретной задачи? Этот вопрос очень
тщательно прорабатывается в программировании.
Эффективность программы (кода) является очень
важной ее характеристикой. Пользователь всегда
предпочитает более эффективное решение даже в
тех случаях, когда эффективность не является
решающим фактором.
Эффективность программы имеет две составляющие:
память (или пространство) и время.
Пространственная эффективность измеряется
количеством памяти, требуемой для выполнения
программы.
Компьютеры обладают ограниченным объемом
памяти. Если две программы реализуют идентичные
функции, то та, которая использует меньший объем
памяти, характеризуется большей
пространственной эффективностью. Иногда память
становится доминирующим фактором в оценке
эффективности программ. Однако в последний годы
в связи с быстрым ее удешевлением эта
составляющая эффективности постепенно теряет
свое значение.
Временная эффективность программы
определяется временем, необходимым для ее
выполнения.
Лучший способ сравнения эффективностей
алгоритмов состоит в сопоставлении их порядков
сложности. Этот метод применим как к временной,
так и пространственной сложности. Порядок
сложности алгоритма выражает его эффективность
обычно через количество обрабатываемых данных.
Например, некоторый алгоритм может существенно
зависеть от размера обрабатываемого массива.
Если, скажем, время обработки удваивается с
удвоением размера массива, то порядок временной
сложности алгоритма определяется как размер
массива.
Порядок алгоритма - это функция, доминирующая
над точным выражением временной сложности.
Функция f(n) имеет порядок O(g(n)), если имеется
константа К и счетчик n0, такие, что f(n)(K*g(n), для n>n0.
Например:
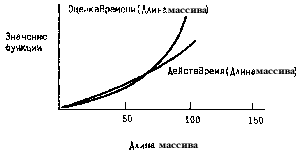
Известно, что точное время обработки массива
Действительное время(Длина массива)= Длина
массива2+5*Длина массива+100;
Вспомогательная функция: Оценка
времени(Длина массива)=1,1* Длина массива2
Как видно из рисунка вспомогательная функция
доминирует над точной, кроме того
вспомогательная функция проще и близка к точной
на столько на сколько это возможно.
Тогда порядок алгоритма обработки массива
будет O(Длина массива2) или O(N2).
O-функции выражают относительную скорость
алгоритма в зависимости от некоторой переменной
(или переменных).
Существуют три важных правила для определения
сложности.
1. O(k*f)=O(f)
2. O(f*g)=O(f)*O(g) или O(f/g)=O(f)/O(g)
3. O(f+g) равна доминанте O(f) и O(g)
Здесь k обозначает константу, a f и g - функции.
Первое правило, приведенное на рисунке,
декларирует, что постоянные множители не имеют
значения для определения порядка сложности.
1,5*N=O(N)
Из второго правила следует, что порядок
сложности произведения двух функций равен
произведению их сложностей.
O((17*N)*N) = O(17*N)*O(N) = O(N)*O(N)=O(N*N) = O(N2)
Из третьего правила следует, что порядок
сложности суммы функций определяется как
порядок доминанты первого и второго слагаемых,
т.е. выбирается наибольший порядок.
O(N5+N2)=O(N5)
O-сложность алгоритмов.
O(1)
Большинство операций в программе выполняются
только раз или только несколько раз. Алгоритмами
константной сложности. Любой алгоритм, всегда
требующий независимо от размера данных одного и
того же времени, имеет константную сложность.
О(N)
Время работы программы линейно обычно когда
каждый элемент входных данных требуется
обработать лишь линейное число раз.
О(N2), О(N3), О(Nа)
Полиномиальная сложность. О(N2)-квадратичная
сложность, О(N3)- кубическая сложность
О(Log(N))
Когда время работы программы логарифмическое,
программа начинает работать намного медленнее с
увеличением N. Такое время работы встречается
обычно в программах, которые делят большую
проблему в маленькие и решают их по отдельности.
O(N*log( N))
Такое время работы имеют те алгоритмы, которые
делят большую проблему в маленькие, а затем,
решив их, соединяют их решения.
O(2N)
Экспоненциальная сложность. Такие алгоритмы
чаще всего возникают в результате подхода
именуемого метод грубой силы.
Программист должен уметь проводить анализ
алгоритмов и определять их сложность. Временная
сложность алгоритма может быть посчитана исходя
из анализа его управляющих структур.
Алгоритмы без циклов и рекурсивных
вызовов имеют константную сложность. Если нет
рекурсии и циклов, все управляющие структуры
могут быть сведены к структурам константной
сложности. Следовательно, и весь алгоритм также
характеризуется константной сложностью.
Определение сложности алгоритма в основном
сводится к анализу циклов и рекурсивных вызовов.
Например, рассмотрим алгоритм обработки
элементов массива.
For i:=1 to N do
Begin
...
End;
Сложность этого алгоритма O(N), т.к. тело цикла
выполняется N раз, и сложность тела цикла равна
O(1).
Если один цикл вложен в другой и оба цикла
зависят от размера одной и той же переменной, то
вся конструкция характеризуется квадратичной
сложностью.
For i:=1 to N do
For j:=1 to N do
Begin
...
End;
Сложность этой программы О(N2).
Давайте оценим сложность программы "Тройки
Пифагора"
Существуют два способа анализа сложности
алгоритма: восходящий (от внутренних управляющих
структур к внешним) и нисходящий (от внешних и
внутренним).
O(H)=O(1)+O(1)+O(1)=O(1);
O(I)=O(N)*(O(F)+O(J))=O(N)*O(доминанты условия)=О(N);
O(G)=O(N)*(O(C)+O(I)+O(K))=O(N)*(O(1)+O(N)+O(1))=O(N2);
O(E)=O(N)*(O(B)+O(G)+O(L))=O(N)* O(N2)= O(N3);
O(D)=O(A)+O(E)=O(1)+ O(N3)= O(N3)
Сложность данного алгоритма O(N3).
Как правило, около 90% времени работы программы
требует выполнение повторений и только 10%
составляют непосредственно вычисления. Анализ
сложности программ показывает, на какие
фрагменты выпадают эти 90% -это циклы наибольшей
глубины вложенности. Повторения могут быть
организованы в виде вложенных циклов или
вложенной рекурсии.
Эта информация может использоваться
программистом для построения более эффективной
программы следующим образом. Прежде всего можно
попытаться сократить глубину вложенности
повторений. Затем следует рассмотреть
возможность сокращения количества операторов в
циклах с наибольшей глубиной вложенности. Если 90%
времени выполнения составляет выполнение
внутренних циклов, то 30%-ное сокращение этих
небольших секций приводит к 90%*30%=27%-му снижению
времени выполнения всей программы.
Это наиболее простой пример.
Анализом эффективности алгоритмов занимается
отдельный раздел математики и найти наиболее
оптимальную функцию бывает не так - то и просто.
Давайте оценим алгоритм бинарного поиска в
массиве - дихотомию.
Суть алгоритма: идем к середине массива и ищем
соответствие ключа значению срединного
элемента. Если нам не удается найти соответствия,
мы смотрим на относительный размер ключа и
значение срединного элемента и затем
перемещаемся в нижнюю или верхнюю половину
списка. В этой половине снова ищем середину и
опять сравниваем с ключом. Если не получается,
снова делим на половину текущий интервал.
function search(low, high, key: integer): integer;
var
mid, data: integer;
begin
while low<=high do
begin
mid:=(low+high) div 2;
data:=a[mid];
if key=data then
search:=mid
else
if key < data then
high:=mid-1
else
low:=mid+1;
end;
search:=-1;
end;
Решение:
Первая итерация цикла имеет дело со всем
списком. Каждая последующая итерация делит
пополам размер подсписка. Так, размерами списка
для алгоритма являются
n n/21 n/22 n/23 n/24 ... n/2m
В конце концов будет такое целое m, что
n/2m<2 или n<2m+1
Так как m - это первое целое, для которого n/2m<2,
то должно быть верно
n/2m-1>=2 или 2m=<n
Из этого следует, что
2m=<n<2m+1
Возьмем логарифм каждой части неравенства и
получим
m=<log2n=x<m+1
Значение m - это наибольшее целое, которое =<х.
Итак, O(log2n).
Обычно решаемая задача имеет естественный
"размер" (обычно количество данных ею
обрабатываемых) которое мы называем N. В конечном
итоге нам бы хотелось получить выражение для
времени, необходимого программе для обработки
данных размера N, как функцию от N. Обычно на
интересует средний случай - ожидаемое время
работы программы на "типичных" входных
данных, и худший случай - ожидаемое время работы
программы на самых плохих входных данных.
Некоторые алгоритмы хорошо изучены в том
смысле, что известны точные математические
формулы для среднего и худшего случаев. Такие
формулы разрабатываются посредством
тщательного изучения программ с целью
нахождения времени работы в терминах
математических характеристик, и затем производя
их математический анализ.
Несколько важных причин такого рода анализа:
1. Программы, написанные на языке высокого уровня,
транслируются в машинные коды, и понять сколько
времени потребуется для выполнения того или
иного оператора может быть трудно.
2. Многие программы очень чувствительны к входным
данным, и их эффективность может очень сильно от
них зависеть. Средний случай может оказаться
математической фикцией не связанной с теми
данными на которых программа используется, а
худший случай маловероятен.
Лучший, средний и худший случаи очень большое
влияние играют в сортировке.
Объем вычислений при сортировке
O-анализ сложности получил широкое
распространение во многих практических
приложениях. Тем не менее необходимо четко
понимать его ограниченность.
К основным недостаткам подхода можно отнести
следующие:
1) для сложных алгоритмов получение O-оценок, как
правило, либо очень трудоемко, либо практически
невозможно,
2) часто трудно определить сложность "в
среднем",
3) O-оценки слишком грубые для отображения более
тонких отличий алгоритмов,
4) O-анализ дает слишком мало информации (или вовсе
ее не дает) для анализа поведения алгоритмов при
обработке небольших объемов данных.
Определение сложности в O-обозначениях - далеко
нетривиальная задача. В частности, эффективность
двоичного поиска определяется не глубиной
вложенности циклов, а способом выбора каждой
очередной попытки.
Еще одна сложность - определение "среднего
случая". Обычно сделать это достаточно трудно
из-за невозможности предсказания условий работы
алгоритма. Иногда алгоритм используется как
фрагмент большой, сложной программы. Иногда
эффективность работы аппаратуры и/или
операционной системы, или некоторой компоненты
компилятора существенно влияет на сложность
алгоритма. Часто один и тот же алгоритм может
использоваться в множестве различных
приложений.
Из-за трудностей, связанных с проведением
анализа временной сложности алгоритма "в
среднем", часто приходится довольствоваться
оценками для худшего и лучшего случаев. Эти
оценки по сути определяют нижнюю и верхнюю
границы сложности "в среднем". Собственно,
если не удается провести анализ сложности
алгоритма "в среднем", остается следовать
одному из законов Мерфи, согласно которому
оценка, полученная для наихудшего случая, может
служить хорошей аппроксимацией сложности "в
среднем".
Возможно, основным недостатком O-функций
является их черезмерная грубость. Если алгоритм
А выполняет некоторую задачу за 0.001*N с, в то время
как для ее же решения с помощью алгоритма В
требуется 1000*N с, то В в миллион раз быстрее, чем А.
Тем не менее А и В имеют одну и ту же временную
сложность O(N).
Большая часть данной лекции была посвящена
анализу временной сложности алгоритмов.
Существуют еще и другие формы сложности, о
которых не следует забывать: пространственная и
интеллектуальная сложность.
О пространственной сложности как объеме
памяти, необходимой для выполнения программы,
уже упоминалось ранее.
При анализе интеллектуальной сложности
алгоритма исследуется понятность алгоритмов и
сложность их разработки.
Все три формы сложности обычно взаимосвязаны.
Как правило, при разработке алгоритма с хорошей
временной оценкой сложности приходится
жертвовать его пространственной и/или
интеллектуальной сложностью. Например, алгоритм
быстрой сортировки существенно быстрее, чем
алгоритм сортировки выборками. Плата за
увеличение скорости сортировки выражена в
большем объеме необходимой для сортировки
памяти. Необходимость дополнительной памяти для
быстрой сортировки связана с многократными
рекурсивными вызовами.
Алгоритм быстрой сортировки характеризуется
также и большей интеллектуальной сложностью по
сравнению с алгоритмом сортировки вставками.
Если предложить сотне людей отсортировать
последовательность объектов, то вероятнее всего,
большинство из них используют алгоритм
сортировки выборками. Маловероятно также, что
кто-то из них воспользуется быстрой сортировкой.
Причины большей интеллектуальной и
пространственной сложности быстрой сортировки
очевидны: алгоритм рекурсивный, его достаточно
трудно описать, алгоритм длиннее (имеется в виду
текст программы), чем более простые алгоритмы
сортировки.
Итак, на сегодняшнем занятии мы рассмотрели
анализ алгоритмов и оценку программ. |