Быстрая сортировка
Цель: изучение алгоритма быстрой сортировки и
ее модификаций.
На этом занятии мы изучим алгоритм быстрой
сортировки, который, пожалуй, используется более
часто, чем любой другой. Основа алгоритма была
разработана в 1960 году (C.A.R.Hoare) и с тех пор
внимательно изучалась многими людьми. Быстрая
сортировка особенно популярна ввиду легкости ее
реализации; это довольно хороший алгоритм общего
назначения, который хорошо работает во многих
ситуациях, и использует при этом меньше ресурсов,
чем другие алгоритмы.
Основные достоинства этого алгоритма состоят в
том, что он точечный (использует лишь небольшой
дополнительный стек), в среднем требует только
около N log N операций для того, чтобы отсортировать
N элементов, и имеет экстремально короткий
внутренний цикл. Недостатки алгоритма состоят в
том, что он рекурсивен (реализация очень
затруднена когда рекурсия недоступна), в худшем
случае он требует N2 операций, кроме того он очень
"хрупок": небольшая ошибка в реализации,
которая легко может пройти незамеченной, может
привести к тому, что алгоритм будет работать
очень плохо на некоторых файлах.
Производительность быстрой сортировки хорошо
изучена. Алгоритм подвергался математическому
анализу, поэтому существуют точные
математические формулы касающиеся вопросов его
производительности. Результаты анализа были
неоднократно проверены эмпирическим путем, и
алгоритм был отработан до такого состояния, что
стал наиболее предпочтительным для широкого
спектра задач сортировки. Все это делает
алгоритм стоящим более детального изучения
наиболее эффективных путей его реализации.
Похожие способы реализации подходят также и для
других алгоритмов, но в алгоритме быстрой
сортировки мы можем использовать их с
уверенностью, поскольку его производительность
хорошо изучена.
Улучшить алгоритм быстрой сортировки является
большим искушением: более быстрый алгоритм
сортировки - это своеобразная "мышеловка"
для программистов. Почти с того момента, как Oia?a
впервые опубликовал свой алгоритм, в литературе
стали появляться "улучшенные" версии этого
алгоритма. Было опробовано и проанализировано
множество идей, но все равно очень просто
обмануться, поскольку алгоритм настолько хорошо
сбалансирован, что результатом улучшения в одной
его части может стать более сильное ухудшение в
другой его части. Мы изучим в некоторых деталях
три модификации этого алгоритма, которые дают
ему существенное улучшение.
Хорошо же отлаженная версия быстрой сортировки
скорее всего будет работать гораздо быстрее, чем
любой другой алгоритм. Однако стоит еще раз
напомнить, что алгоритм очень хрупок и любое его
изменение может привести к нежелательным и
неожиданным эффектам для некоторых входных
данных.
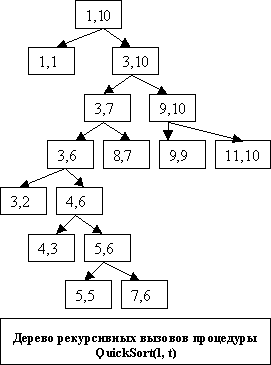
Суть алгоритма: число операций перемены
местоположений элементов внутри массива
значительно сократится, если менять местами
далеко стоящие друг от друга элементы. Для этого
выбирается для сравнения один элемент х,
отыскивается слева первый элемент, который не
меньше х, а справа первый элемент, который не
больше х. Найденные элементы меняются местами.
После первого же прохода все элементы, которые
меньше х, будут стоять слева от х, а все элементы,
которые больше х, - справа от х. С двумя половинами
массива поступают точно также. Продолжая деление
этих половин до тех пор пока не останется в них по
1 элементу.
program Quitsort;
uses
crt;
Const
N=10;
Type
Mas=array[1..n] of integer;
var
a: mas;
k: integer;
function Part(l, r: integer):integer;
var
v, i, j, b: integer;
begin
V:=a[r];
I:=l-1;
j:=r;
repeat
repeat
dec(j)
until (a[j]<=v) or (j=i+1);
repeat
inc(i)
until (a[i]>=v) or (i=j-1);
b:=a[i];
a[i]:=a[j];
a[j]:=b;
until i>=j;
a[j]:=a[i];
a[i]:= a[r];
a[r]:=b;
part:=i;
end;
procedure QuickSort(l, t: integer);
var i: integer;
begin
if l<t then
begin
i:=part(l, t);
QuickSort(l,i-1);
QuickSort(i+1,t);
end;
end;
begin
clrscr;
randomize;
for k:=1 to 10 do
begin
a[k]:=random(100);
write(a[k]:3);
end;
QuickSort(1,n);
writeln;
for k:=1 to n do
write(a[k]:3);
readln;
end.
Пример:
60,79, 82, 58, 39, 9, 54, 92, 44, 32
60,79, 82, 58, 39, 9, 54, 92, 44, 32
9,79, 82, 58, 39, 60, 54, 92, 44, 32
9,79, 82, 58, 39, 60, 54, 92, 44, 32
9, 32, 82, 58, 39, 60, 54, 92, 44, 79
9, 32, 44, 58, 39, 60, 54, 92, 82, 79
9, 32, 44, 58, 39, 54, 60, 92, 82, 79
9, 32, 44, 58, 39, 92, 60, 54, 82, 79
9, 32, 44, 58, 39, 54, 60, 79, 82, 92
9, 32, 44, 58, 54, 39, 60, 79, 82, 92
9, 32, 44, 58, 60, 39, 54, 79, 82, 92
9, 32, 44, 58, 54, 39, 60, 79, 82, 92
9, 32, 44, 58, 54, 39, 60, 79, 82, 92
9, 32, 44, 58, 54, 39, 60, 79, 82, 92
9, 32, 39, 58, 54, 44, 60, 79, 82, 92
9, 32, 39, 58, 54, 44, 60, 79, 82, 92
9, 32, 39, 44, 54, 58, 60, 79, 82, 92
9, 32, 39, 44, 58, 54, 60, 79, 82, 92
9, 32, 39, 44, 54, 58, 60, 79, 82, 92
9, 32, 39, 44, 54, 58, 60, 79, 92, 82
9, 32, 39, 44, 54, 58, 60, 79, 82, 92
"Внутренний цикл" быстрой
сортировки состоит только из увеличения
указателя и сравнения элементов массива с
фиксированным числом. Это как раз и делает
быструю сортировку быстрой. Сложно придумать
более простой внутренний цикл. Положительные
эффекты сторожевых ключей также оказывают здесь
свое влияние, поскольку добавление еще одной
проверки к внутреннему циклу оказало бы
отрицательное влияние на производительность
алгоритма.
Самая сомнительная черта вышеприведенной
программы состоит в том, что она очень мало
эффективна на простых подфайлах. Например, если
файл уже сортирован, то разделы будут
вырожденными, и программа просто вызовет сама
себя N раз, каждый раз с меньшим на один элемент
подфайлом. Это означает, что не только
производительность программы упадет примерно до
N2/2, но и пространство необходимое для ее
работы будет около N (смотри ниже), что
неприемлемо. К счастью, есть довольно простые
способы сделать так, чтобы такой "худший"
случай не произошел при практическом
использовании программы.
Когда в файле присутствуют одинаковые ключи, то
возникает еще два сомнительных вопроса. Первое,
должны ли оба указателя останавливаться на
ключах равных делящему элементу или
останавливать только один из них, а второй будет
проходить их все, или оба указателя должны
проходить над ними. На самом деле, этот вопрос
детально изучался, и результаты показали, что
самое лучшее - это останавливать оба указателя.
Это позволяет удерживать более или менее
сбалансированные разделы в присутствии многих
одинаковых ключей. На самом деле, эта программа
может быть слегка улучшена терминированием
сканирования j<i, и использованием после этого
quicksort(l, j) для первого рекурсивного вызова.
Характеристики Производительности
Быстрой Сортировки
Самое лучшее, что могло бы произойти для
алгоритма - это если бы каждый из подфайлов
делился бы на два равных по величине подфайла. В
результате количество сравнений делаемых
быстрой сортировкой было бы равно значению
рекурсивного выражения
CN = 2CN/2+N - наилучший случай.
(2CN/2 покрывает расходы по сортировке двух
полученных подфайлов; N - это стоимость обработки
каждого элемента, используя один или другой
указатель.) Нам известно также, что примерное
значение этого выражения равно CN = N lg N.
Хотя мы встречаемся с подобной ситуацией не так
часто, но в среднем время работы программы будет
соответствовать этой формуле. Если принять во
внимание вероятные позиции каждого раздела, то
это сделает вычисления более сложными, но
конечный результат будет аналогичным.
Свойство 1 Быстрая сортировка в
среднем использует 2N ln N сравнений.
Методы улучшения быстрой сортировки.
1. Небольшие Подфайлы.
Первое улучшение в алгоритме быстрой
сортировки возникает из наблюдения, что
программа гарантировано вызывает себя для
огромного количества небольших подфайлов,
поэтому следует использовать самый лучший метод
сортировки когда мы встречаем небольшой подфайл.
Очевидный способ добиться этого, это изменить
проверку в начале рекурсивной функции из "if
r>l then" на вызов сортировки вставкой
(соответственно измененной для восприятия
границ сортируемого подфайла): "if r-l<=M then
insertion(l, r)." Значение для M не обязано быть
"самым-самым" лучшим: алгоритм работает
примерно одинаково для M от 5 до 25. Время работы
программы при этом снижается примерно на 20% для
большинства программ.
При небольших подфайлах (5- 25 элементов) быстрая
сортировка очень много раз вызывает сама себя (в
наше примере для 10 элементов она вызвала сама
себя 15 раз), поэтому следует применять не быструю
сортировку, а сортировку вставкой.
procedure QuickSort (l,t:integer);
var
i:integer;
begin
if t-l>m then
begin
i:=part(l,t);
QuickSort (l,i-1);
QuickSort (i+1,t);
end
Else
Insert(l,t);
end;
2. Деление по Медиане из Трех
Второе улучшение в алгоритме быстрой
сортировки состоит в попытке использования
лучшего делящего элемента. У нас есть несколько
возможностей. Наиболее безопасная из них будет
попытка избежать худшего случая посредством
выбора произвольного элемента массива в
качестве делящего элемента. Тогда вероятность
худшего случая становится пренебрежимо мала. Это
простой пример "вероятностного" алгоритма,
который почти всегда работает вне зависимости от
входных данных. Произвольность может быть
хорошим инструментом при разработке алгоритмов,
особенно если возможны подозрительные входные
данные.
Более полезное улучшение состоит в том, чтобы
взять из файла три элемента, и затем использовать
среднее из них в качестве делящего элемента. Если
элементы взяты из начала, середины, и конца файла,
то можно избежать использования сторожевых
элементов: сортируем взятые три элемента, затем
обмениваем центральный элемент с a[r-1], и затем
используем алгоритм деления на массиве a[l+1..r-2].
Это улучшение называется делением по медиане из
трех.
Метод деления по медиане из трех полезен по
трем причинам. Во-первых, он делает вероятность
худшего случая гораздо более низкой. Чтобы этот
алгоритм использовал время пропорциональной N2,
два из трех взятых элементов должны быть либо
самыми меньшими, либо самыми большими, и это
должно повторяться из раздела в раздел.
Во-вторых, этот метод уничтожает необходимость в
сторожевых элементах, поскольку эту роль играет
один из трех взятых нами перед делением
элементов. В третьих, он на самом деле снижает
время работы алгоритма приблизительно на 5%.
procedure exchange(i,j:integer);
var
k:integer;
begin
k:=a[i];
a[i]:=a[j];
a[j]:=k;
end;
procedure Mediana;
var i:integer;
begin
i:=n div 4;{Рис.}
if a[i]>a[i*2] then
if a[i]>a[i*3] then
exchange(i,n)
else
exchange(i*3,n)
else
if a[i*2]>a[i*3] then
exchange(i*2,n);
quicksort(1,n);
end;
3. Нерекурсивная реализация.
Можно переписать данный алгоритм без
использования рекурсии используя стек, но здесь
мы это не будем делать.
Комбинация нерекурсивной реализации деления
по медиане из трех с отсечением на небольшие
файлы может улучшить время работы алгоритма от 25%
до 30%.
Итак, на сегодняшнем занятии мы рассмотрели
алгоритм быстрой сортировки.
|