
Рис.
1.1. Взаимодействие оперативной памяти и процессора.
Выполнив первую команду, процессор переходит к следующей, и так дшгее до конца
программы. Завершив программу, процессор не будет знать, что ему дальше делать,
поэтому любая программа должна завершаться командами, передающими упрашгение
операционной системе компьютера.
Оперативная память компьютера представляет собой электронное устройство, состоящее
из большого числа двоичных запоминающих элементов, а также схем упраштения ими.
Минимальный объем информации, к которому имеется доступ в памяти, состаатяет
один байт (8 двоичных разрядов, или битов). Все байты оперативной памяти нумеруются,
начиная с нуля. Нужные байты отыскиваются в памяти по их номерам, выполняющим
функции адресов.
Некоторые данные (например, коды символов) требуют для своего хранения одного
байта; для других данных этого места на хватает, и под них в памяти выделяется
2, 4, 8 или еще большее число байтов. Обычно пары байтов называют словами, а
четверки - двойными словами (рис. 1.2), хотя иногда термином "слово"
обозначают любую порцию машинной информации.
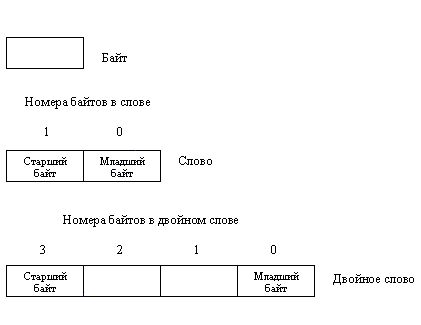
Рис. 1.2. Байт, слово
и двойное слово.
При обсуждении содержимого многобайтового данного приходится ссылаться на составляющие
его байты; эти байты условно нумеруются от нуля и располагаются (при их изображении
на бумаге) в порядке возрастания номера справа налево, так что слева оказываются
байты с большими номерами, а справа - байты с меньшими номерами. Крайний слева
байт принято называть старшим, а крайний справа - младшим. Такой порядок расположения
байтов связан с привычной для нас формой записи чисел: в многоразрядном числе
слева указываются старшие разряды, а справа - младшие. Следующее число, если
его написать за предыдущим, опять начнется со старшего разряда и закончится
младшим. Однако в памяти компьютера данные располагаются в более естественном
порядке непрерывного возрастания номеров байтов и, таким образом, каждое слово
или двойное слово в памяти начинается с его младшего байта и заканчивается старшим
(рис. 1.3).
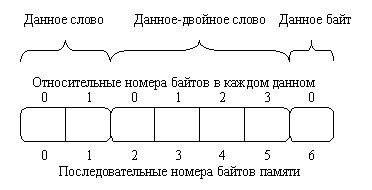
Рис. 1.3. Нумерация байтов в многобайтовых данных.
Строго говоря, в памяти компьютера можно хранить только целые двоичные числа,
так как память состоит из двоичных запоминающих элементов. Для записи иных данных,
например, символов или дробных чисел, для них предусматриваются правила кодирования,
т.е. представления
в виде последовательности битов той или длины. Так, действительное число одинарной
точности занимает в памяти двойное слово (32 бит), в котором 23 бит отводятся
под мантиссу, 8 бит под порядок и еще один бит под знак числа. Программы, работающие
с такого рода данными, должны, естественно, знать правила их записи и руководствоваться
ими при обработке и представлении этих данных.
Двоичная система счисления, в которой работают все цифровые электронные устройства,
неудобна для человека. Для удобства представления двоичного содержимого ячеек
памяти или регистров процессора используют иногда восьмеричную, а чаще - шестнадцатеричную
системы счисления. Для процессоров Intel используется шестнадцатеричная система.
Каждый разряд шестнадцатеричного числа может принимать 16 значений, из которых
первые 10 обозначаются обычными десятичными цифрами, а последние 6 - буквами
латинского алфавита от А до F, где А обозначает 10, В - И, С - 12, D - 13, Е
- 14, a F - 15. В языке ассемблера шестнадцатеричные числа, чтобы отличать их
от десятичных, завершаются буквой h (или Н). Таким образом, 100 - это десятичное
число, a l00h - шестнадцатеричное (равное 256). Поскольку одна шестнадцатеричная
цифра требует для записи ее в память компьютера четырех двоичных разрядов, то
содержимое байта описывается двумя шестнадца-теричными цифрами (от 00h до FFh,
или от 0 до 255) , а содержимое слова - четырьмя (от 0000h до FFFFh, или от
0 до 65535).
Помимо ячеек оперативной памяти, для хранения данных используются еще запоминающие
ячейки, расположенные в процессоре и называемые регистрами. Достоинство регистров
заключается в их высоком быстродействии, гораздо большем, чем у оперативной
памяти, а недостаток в том, что их очень мало - всего около десятка. Поэтому
регистры используются лишь для кратковременного хранения данных. В режиме МП
86, который мы здесь обсуждаем, все регистры процессора имеют длину 16 разрядов,
или 1 слово (в действительности в современных процессорах их длина составляет
32 разряда, но в МП 86 от каждого регистра используется лишь его половина).
За каждым регистром закреплено определенное имя (например, АХ или DS), по которому
к нему можно обращаться в программе. Состав и правила использования регистров
процессора будут подробно описаны ниже, здесь же мы коснемся только назначения
сегментных регистров, с помощью которых осуществляется обращение процессора
к ячейкам оперативной памяти.
Казалось бы, для передачи процессору адреса какого-либо байта оперативной памяти,
достаточно записать в один из регистров процессора его номер. В действительности
поступить таким образом в 16-разрядном процессоре нельзя, так как максимальное
число (данное или адрес), которое можно записать в 16-разрядный регистр, составляет
всего 216 - 1 = 65535, или 64К-1, и мы получим возможность обращения лишь к
первым 64 Кбайт памяти. Для того, чтобы с помощью 16-разрядных чисел адресовать
любой байт памяти, в МП 86 предусмотрена сегментная адресация памяти, реализуемая
с помощью сегментных регистров процессора.
Суть сегментной адресации заключается в следующем. Обращение к памяти осуществляется
исключительно с помощью сегментов - логических образований, накладываемых на
те или иные участки физической памяти. Исполнительный адрес любой ячейки памяти
вычисляется процессором путем сложения начального адреса сегмента, в котором
располагается эта ячейка, со смещением к ней (в байтах) от начала сегмента (рис.
1.4). Это смещение иногда называют относительным адресом.
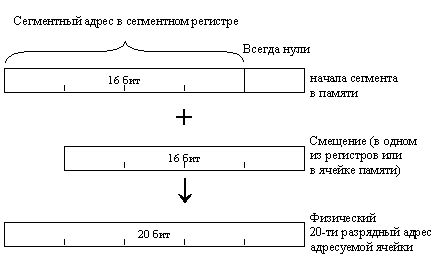
Рис. 1.4. Образование
физического адреса из сегментного адреса и смещения.
Начальный адрес сегмента без четырех младших битов, т.е. деленный на 16, помещается
в один из сегментных регистров и называется сегментным адресом. Сам же начальный
адрес хранится в специальном внутреннем регистре процессора, называемом теневым
регистром. Для каждого сегментного регистра имеется свой теневой регистр; начальный
адрес сегмента загружается в него процессором в тот момент, когда программа
заносит в соответствующий сегментный регистр новое значение сегментного адреса.
Процедура умножения сегментного адреса на 16 (или, что то же самое, на 10h)
является принципиальной особенностью реального режима, ограничивающей диапазон
адресов, доступных в реальном режиме, величиной 1 Мбайт. Действительно, максимальное
значение сегментного адреса составляет FFFFh, или 64К-1, из чего следует, что
максимальное значение начального адреса сегмента в памяти равно FFFF0h, или
1 Мбайт - 16. Если, однако, учесть, что к начальному адресу сегмента можно добавить
любое смещение в диапазоне от 0 до FFFFh, то адрес последнего адресуемого байта
окажется равен 10FFEFh, что соответствует величине 1 Мбайт + 64 Кбайт - 17.
Диапазон адресов, формируемых процессором, называют адресным пространством процессора;
как мы видим, в реальном режиме он немного превышает 1 Мбайт. Заметим еще, что
для описания адреса в пределах 1 Мбайт требуются 20 двоичных разрядов, или 5
шестнадцатеричных. Процессор 8086 имел как раз 20 адресных линий и не мог, следовательно,
выйти за пределы 1 Мбайт; современным 32-разрядным процессорам, если они работают
в реатьном режиме, доступно несколько большее (почти на 64 Кбайт) адресное пространство.
Если же процессор работает в защищенном режиме (с использованием 32-разрядных
регистров), то его адресное пространство увеличивается до 232 = 4 Гбайт.
1.2.
Распределение адресного пространства
Не следует думать, что термины "адресное пространство" и "оперативная память" эквивалентны. Адресное пространство - это просто набор адресов, которые умеет формировать процессор; совсем не обязательно все эти адреса отвечают реально существующим ячейкам памяти. В зависимости от модификации персонального компьютера и состава его периферийного оборудования, распределение адресного пространства может несколько различаться. Тем не менее, размещение основных компонентов системы довольно строго унифицировано. Типичная схема использования адресного пространства компьютера приведена на рис. 1.5. Значения адресов на этом рисунке, как и повсюду дшгее в книге, даны в шестнадцатеричной системе счисления.
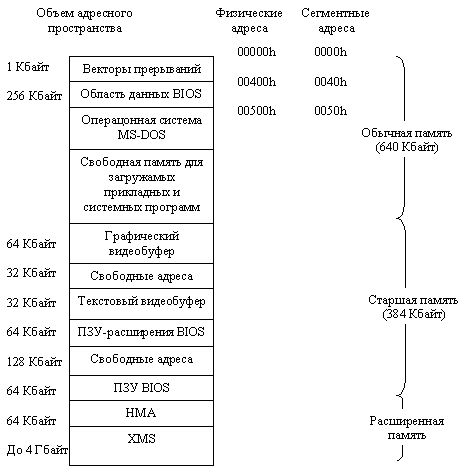
Рис. 1.5. Типичное распределение
адресного пространства.
Первые 640 Кбайт адресного пространства с адресами от 00000h до 9FFFF11 (и,
соответственно, с сегментными адресами от 0000h до 9FFFh) отводятся под основную
оперативную память, которую еще называют стандартной (conventional). Начальный
килобайт оперативной памяти занят векторами прерываний, которые обеспечивают
работу системы прерываний компьютера, и включает 256 векторов по 4 байта каждый.
Вслед за векторами прерываний располагается так называемая область данных BIOS,
которая занимает всего 256 байт, начиная с сегментного адреса 40h. Сама BIOS
(от Basic In-Out System, базовая система ввода-вывода) является частью операционной
системы, хранящейся в постоянном запоминающем устройстве. Это запоминающее устройство
(ПЗУ BIOS) располагается на системной плате компьютера и является, таким образом,
примером встроенного, или "зашитого" программного обеспечения. В функции
BIOS входит тестирование компьютера при его включении, загрузка в оперативную
память собственно операционной системы MS-DOS, хранящейся на магнитных дисках,
а также управление штатной аппаратурой компьютера - клавиатурой, экраном, дисками
и прочим. В области данных BIOS хранятся разнообразные данные, используемые
программами BIOS в своей работе. Так, здесь размещаются:
- входной буфер клавиатуры, куда поступают коды нажимаемых пользователем клавиш;
- адреса видеоадаптера, а также последовательных и параллельных портов;
- данные, характеризующие текущее состояние видеосистемы (форма курсора и его
текущее положение на экране, видеорежим, используемая видеостраница и проч.);
- ячейки для отсчета текущего времени и т.д.
Область данных BIOS заполняется информацией в процессе начальной загрузки компьютера,
а затем динамически модифицируется системой по мере необходимости. Многие прикладные
программы, особенно, написанные на языке ассемблера, обращаются к этой области
с целью чтения или модификации содержащихся в них данных. С некоторыми ячейками
области данных BIOS мы столкнемся при рассмотрении примеров конкретных программ.
В области памяти, начиная с адреса 500h, располагается собственно операционная
система MS-DOS, которая обычно занимает несколько десятков Кбайт. Программы
MS-DOS, как и другие системные состаатя-ющие (векторы прерываний, область данных
BIOS) записываются в память автоматически в процессе начальной загрузки компьютера.
Вся оставшаяся память до границы 640 Кбайт свободна для загрузки любых системных
или прикладных программ. Как правило, в начале сеанса в память загружают резидентные
программы (русификатор, антивирусные программы). При наличии резидентных программ
объем свободной памяти уменьшается.
Оставшиеся 384 Кбайт адресного пространства между границами 640 Кбайт и 1 Мбайт,
называемые старшей, или верхней (upper) памятью, первоначально были предназначены
для размещения постоянных запоминающих устройств (ПЗУ). Практически под ПЗУ
занята только небольшая часть адресов, а остальные используются в других целях.
Часть адресного пространства старшей памяти отводится для адресации к графическому
и текстовому видеобуферам графического адаптера. Графический адаптер представляет
собой отдельную микросхему или даже отдельную плату, в состав которой входит
собственное запоминающее устройство (видеопамять). Это запоминающее устройство
не имеет никакого отношения к оперативной памяти компьютера, однако, его схемы
управления настроены на диапазоны адресов A0000h...AFFFFh и B8000h...BFFFFh,
входящих в общее с памятью адресное пространство процессора. Поэтому любая программа
может обратиться по этим адресам и, например, записать данные в видеобуфер,
что приведет к появлению на экране некоторого изображения. Бели видеосистема
находится в текстовом режиме, а запись осуществляется по адресам текстового
видеобуфера, на экране появятся изображения тех или иных символов (букв, цифр,
различных знаков). Если же перевести видеосистему в графический режим, и записывать
данные в графический видеобуфер, то на экране появятся отдельные точки или линии.
Можно также прочитать текущее содержимое ячеек видеобуфера.
В самом конце адресного пространства, в области адресов F0000h...FFFFFh, располагается
ПЗУ BIOS - постоянное запоминающее устройство, о котором уже говорилось выше.
Часть адресного пространства, начиная с адреса C0000h, отводится еще под одно
ПЗУ - так называемое ПЗУ расширений BIOS для обслуживания графических адаптеров
и дисков.
В состав компьютера, наряду со стандартной памятью (640 Кбайт), входит еще расширенная
(extended) память, максимальный объем которой может доходить до 4 Гбайт. Эта
память располагается за пределами первого мегабайта адресного пространства и
начинается с адреса 100000h. Реально на машине может быть установлен не полный
объем расширенной памяти, а лишь несколько десятков Мбайт или даже меньше.
Поскольку функционирование расширенной памяти подчиняется "спецификации
расширенной памяти" (Extended Memory Specification, сокращенно XMS), то
и саму память часто называют XMS-памятью. Как уже отмечалось выше, доступ к
расширенной памяти осуществляется в защищенном режиме, поэтому для MS-DOS, работающей
только в реальном режиме, расширенная память недоступна. Однако в современные
версии MS-DOS включается драйвер HIMEM.SYS, поддерживающий расширенную память,
т.е. позволяющий ее использовать, хотя и ограниченным образом. Конкретно в расширенной
памяти можно разместить электронные диски (с помощью драйвера RAMDRIVE.SYS)
или дисковые кэш-буферы (с помощью драйвера SMARTDRV.SYS).
Первые 64 Кбайт расширенной памяти, точнее, 64 Кбайт - 16 байт с адресами от
l00000h до l0FFEFh, носят специальное название область старшей памяти (High
MemoryArea, HMA). Эта область замечательна тем, что хотя она находится за пределами
первого мегабайта, к ней можно обратиться в реальном режиме работы микропроцессора,
если определить сегмент, начинающийся в самом конце мегабайтного адресного пространства,
с сегментного адреса FFFFh, и разрешить использование адресной линии А20. Первые
16 байт этого сегмента заняты ПЗУ, область же со смещениями 0010h...FFFFh можно
в принципе использовать под программы и данные. MS-DOS позволяет загружать в
НМЛ (директивой файла CONFIG.SYS DOS=HIGH) значительную часть самой себя, в
результате чего занятая системой область стандартной памяти существенно уменьшается.
Старшую память обслуживает тот же драйвер HIMEM.SYS, поэтому загрузка DOS в
НМЛ возможна, только если установлен драйвер HIMEM.SYS.
Как видно из приведенного выше рисунка, часть адресного пространства верхней
памяти, не занятая расширениями BIOS и видеобуферами, оказывается свободной.
Эти свободные участки можно использовать для адресации к расширенной памяти
(конечно, не ко всей, а лишь к той ее части, объем которой совпадает с общим
объемом свободных адресов старшей памяти). Отображение расширенной памяти на
свободные адреса старшей памяти выполняет драйвер EMM386.EXE, а сами участки
старшей памяти, "заполненные" расширенной, называются блоками верхней
памяти (Upper Memory B10cks, UMB). MS-DOS позволяет загружать в UMB устанавливаемые
драйверы устройств, а также резидентные программы. Загрузка системных программ
в UMB освобождает от них стандартную память, увеличивая ее транзитную область.
Загрузка в UMB драйверов осуществляется директивой файла CONFIG.SYS DEVICEHIGH
(вместо директивы DEVICE), а загрузка резидентных программ - командой DOS 10ADHIGH.
На оптимально сконфигурированном компьютере системными компонентами заняты лишь
около 20...25 Кбайт основной памяти, а вся остальная память в объеме около 620
Кбайт может использоваться для загрузки прикладных программ.
Как уже отмечалось выше,
в современных микропроцессорах типа, например, Pentium, можно выделить часть
(мы назвали ее МП 86), предназначенную для использования в реальном режиме и
практически соответствующую процессору 8086. Ниже, используя термин "процессор",
мы будем иметь в виду именно МП 86.
Процессор содержит двенадцать 16-разрядных программно-адресуемых регистров,
которые принято объединять в три группы: регистры данных, регистры-указатели
и сегментные регистры. Регистры данных и регистры-указатели часто объединяют
под общим названием "регистры общего назначения". Кроме того, в состав
процессора входят указатель команд и регистр флагов (рис. 1.6).
В группу регистров данных включаются четыре регистра АХ, ВХ, СХ и DX. Программист
может использовать их по своему усмотрению для временного хранения любых объектов
(данных или адресов) и выполнения над ними требуемых операций. При этом регистры
допускают независимое обращение к старшим (АН, ВН, СН и DH) и младшим (AL, BL,
CL и DL) половинам. Так, команда
mov BL, АН
пересылает
старший байт регистра АХ в младший байт регистра ВХ, не затрагивая при этом
вторых байтов этих регистров. Заметьте, что сначала указывается операнд-приемник,
а после запятой - .операнд-источник, т.е. команда как бы выполняется справа
налево.
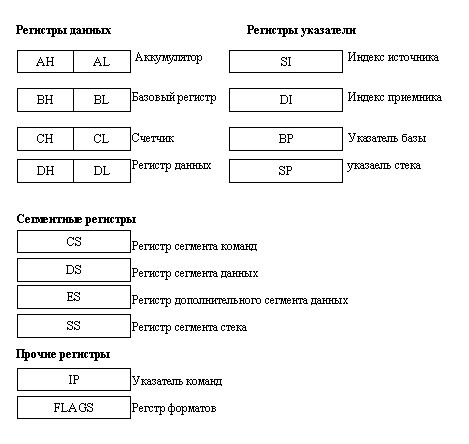
Рис. 1.6. Регистры процессора.
Во многих случаях регистры данных вполне эквивалентны, однако предпочтительнее
пользоваться регистром АХ, поскольку многие команды занимают в памяти меньше
места и выполняются быстрее, если их операндом является регистр АХ (или его
половина AL). С другой стороны, ряд команд использует определенные регистры
неявным образом. Так, все команды циклов используют регистр СХ в качестве счетчика
числа повторений; в командах умножения и деления регистры АХ и DX выступают
в качестве неявных операндов; операции ввода-вывода можно осуществлять только
через регистры АХ или AL и т.д.
Индексные регистры SI и DI так же, как и регистры данных, могут использоваться
произвольным образом. Однако их основное назначение - хранить индексы, или смещения
относительно некоторой базы (т.е. начала массива) при выборке операндов из памяти.
Адрес базы при этом может находиться в базовых регистрах ВХ или ВР. Специально
предусмотренные команды работы со строками используют регистры SI и DI в качестве
неявных указателей в обрабатываемых строках.
Регистр ВР служит указателем базы при работе с данными в стековых структурах,
но может использоваться и произвольным образом в большинстве арифметических
и логических операций.
Последний из группы регистров-указателей, указатель стека SP, стоит особняком
от других в том отношении, что используется исключительно как указатель вершины
стека - специальной структуры, которая будет рассмотрена ниже.
Регистры SI, DI, BP и SP, в отличие от регистров данных, не допускают побайтовую
адресацию.
Четыре сегментных регистра CS, DS, ES и SS являются важнейшим элементом архитектуры
процессора, обеспечивая, как уже отмечалось выше, адресацию 20-разрядного адресного
пространства с помощью 16-разрядных операндов. Подробнее о них будет рассказано
в следующем разделе.
Указатель команд IP "следит" за ходом выполнения программы, указывая
в каждый момент относительный адрес команды, следующей за исполняемой. Регистр
IP программно недоступен (IP - это просто его сокращенное название, а не мнемоническое
обозначение, используемое в языке программирования); наращивание адреса в нем
выполняет микропроцессор, учитывая при этом длину текущей команды. Команды переходов,
прерываний, вызова подпрограмм и возврата из них изменяют содержимое IP, осуществляя
тем самым переходы в требуемые точки программы. В следующем разделе мы еще вернемся
к роли регистра IP в выполнении программы.
Регисдр флагов (его часто называют FLAGS), эквивалентный регистру состояния
процессора других вычислительных систем, содержит информацию о текущем состоянии
процессора (рис. 1.7). Он включает 6 флагов состояния и 3 бита управления состоянием
процессора, которые, впрочем, тоже называются флагами.
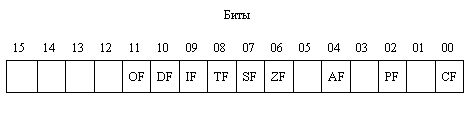
Рис. 1.7. Регистр флагов
Флаги состояния заново
устанавливаются процессором после выполнения каждой очередной команды, и по
ним можно в какой-то степени судить о результате выполнения этой команды (например,
не равен ли ее результат, нулю). Флаги управления позволяют изменять некоторые
условия работы процессора, например, разрешать или запрещать аппаратные прерывания.
Рассмотрим сначала флаги состояния.
Флаг переноса CF (Carry Flag) индицирует перенос или заем при выполнении арифметических
операций. Переносом называется ситуация, когда в результате выполнения правильной,
в общем, команды образуется число, содержащее более 16 двоичных разрядов и,
следовательно, не помещающееся в регистр или ячейку памяти. Пусть, например,
в регистре АХ содержится число 60000, а в регистре ВХ - 40000. При выполнении
команды сложения
add AX,BX
в регистре-приемнике результата,
которым в данном случае будет служить регистр АХ, должно быть записано число
100000, которое, разумеется, там поместиться не может. В этом случае и устанавливается
флаг CF, по состоянию которого можно установить, что произошел перенос и, следовательно,
содержимое АХ (которое в данном случае будет равно 100000 - 65536 = 34464) не
является правильным результатом.
Необходимо подчеркнуть, что ситуация переноса, как и вообще любая ошибка, возникшая
по ходу выполнения программы, не приводит ни к каким последствиям, кроме установки
соответствующего флага. Процессор, установив флаг, считает свою миссию выполненной
и переходит к выполнению следующей команды. Если перенос в данном случае действительно
является индикатором ошибки, программа должна после выполнения команды сложения
проанализировать состояние флага CF, и при установленном флаге перейти на фрагмент
обработки этой ошибки. Такой анализ выполняется с помощью команд условного перехода,
в данном случае с помощью команды jc (jump if carry, переход по переносу):add
AX.BX
jc error ;B случае переноса переход ;на метку error ;Нормальное продолжение
Сказанное справедливо по отношению ко всем ошибочным ситуациям, возникающим
в программе, - программа сама обязана отлавливать все ошибки и выполнять предусмотренные
для таких случаев действия. Единственное, что может сделать процессор - это
сообщить программе о подозрительном результате установкой того или иного флага.
Флаг паритета PF (Parity Flag) устанавливается в 1, если результат операции
содержит четное число двоичных единиц, и сбрасывается в О, если число двоичных
единиц нечетно. Этот флаг можно использовать, например, для поиска ошибок при
передаче данных и при выполнении диагностических тестов.
Флаг вспомогательного переноса AF (Auxiliary Flag) используется в операциях
над двоично-десятичными числами. Он индицирует перенос или заем из старшей тетрады
(бита 4). Двоично-десятичный формат подразумевает запись в каждой половинке
байта десятичной цифры в виде ее двоичного эквивалента, что позволяет хранить
в байте двухразрядное десятичное число в диапазоне от 0 до 99 Двоично-десятичные
числа используются, в частности, для обмена данными с измерительными приборами.
Для их обработки в процессоре предусмотрен целый ряд специфических команд, при
использовании которых приходится анализировать состояние флага вспомогательного
переноса
Флаг нуля ZF (Zero Flag) устанавливается в 1, если результат операции равен
0. Например, флаг ZF установится, если из 5 вычесть 5 или к 10 прибавить -10.
Флаг знака SF (Sign Rag) показывает знак результата операции, устанавливаясь
в 1 при отрицательном результате. Как будет показано в следующей главе, процессор
различает числа без знака, т.е. существенно положительные, и числа со знаком,
которые могут быть как положительными, так и отрицательными. Признаком отрицательности
числа служит установленный старший бит этого числа (бит 15 для слов или бит
7 для байтов). Флаг SF устанавливается, если в результате какой-либо операции
сформировано число с установленным старшим битом, например, S000h или FFFFh.
Флаг переполнения OF (Overflow Rag) фиксирует переполнение, т.е. выход результата
за пределы допустимого диапазона значений для чисел со знаком. В знаковом представлении
числа от 0000h до 7FFFh считаются положительными, а числа от S000h до FFFFh,
т.е. числа с установленным старшим битом - отрицательными. Флаг OF устанавливается,
если, например, при сложении двух положительных чисел получился результат, превышающий
7FFFh (потому что, начиная с S000h, идут уже отрицательные числа), или при вычитании
из отрицательного числа получился результат, меньший S000h (потому что такие
числа считаются положительными). Позже этот вопрос будет рассмотрен более детально.
Перейдем теперь к управляющим флагам, которых в регистре флагов реального режима
всего три.
Управляющий флаг трассировки (ловушки) TF (Trace Rag) используется для осуществления
пошагового выполнения программы. Если TF=1, то после выполнения каждой команды
процессор реализует процедуру прерывания через вектор с номером 1, расположенный
по физическому адресу 04. Этот флаг активно используется в программах отладчиков,
которые должны допускать выполнение отлаживаемой программы по шагам или с точками
останова.
Управляющий флаг разрешения прерываний IF (Interrupt Rag) разрешает (если равен
1) или запрещает (если равен 0) процессору реагировать на прерывания от внешних
устройств. Тем самым создается возможность выполнения особо ответственных фрагментов
программ без каких-либо помех.
Управляющий флаг направления DF (Direction Rag) используется командами обработки
строк. Если DF=0, строка обрабатывается в прямом
направлении, от меньших адресов к большим; если DF=1, обработка строки идет
в обратном направлении. Примеры использования этого флага будут приведены при
рассмотрении соответствующих команд процессора.
Для установки и сброса управляющих флагов предусмотрены особые команды, например
sti (set interrupt, установить прерывания) или cli (clear interrupt, сбросить
прерывания).
1.4.
Сегментная структура программ
Как было показано выше,
обращение к памяти осуществляется исключительно посредством сегментов - логических
образований, накладываемых на любые участки физического адресного пространства.
Начальный адрес сегмента, деленный на 16, т.е. без младшей шестнадцатеричной
цифры, заносится в один из сегментных регистров; после этого мы получаем доступ
к участку памяти, начинающегося с заданного сегментного адреса.
Каким образом понятие сегментов памяти отражается на структуре программы? Следует
заметить, что структура программы определяется, с одной стороны, архитектурой
процессора (если обращение к памяти возможно только с помощью сегментов, то
и программа, видимо, должна состоять из сегментов), а с другой - особенностями
той операционной системы, под управлением которой эта программа будет выполняться.
Наконец, на структуру программы влияют также и правила работы выбранного транслятора
- разные трансляторы предъявляют несколько различающиеся требования к исходному
тексту программы. При подготовке этой книги для трансляции и отладки примеров
программ использовался пакет TASM 5.0 корпорации Borland International; он удобен,
в частности, наличием наглядного многооконного отладчика. Вопрос этот, однако,
не принципиален, и читатель может для отладки примеров, приведенных в книге,
воспользоваться любым ассемблером, ознакомившись предварительно с его описанием.
В настоящем разделе мы на простом примере рассмотрим особенности сегментной
адресации и роль регистров процессора в выполнении прикладной программы. Однако
для того, чтобы программа была работоспособна, нам придется включить в нее ряд
элементов, не имеющих прямого отношения к рассматриваемым вопросам, но необходимых
для ее правильного функционирования. К таким элементам, в частности, относится
вызов функций DOS. Приведя полный текст программы, мы дадим краткие пояснения.
;Пример 1-1. Простая программа
с тремя сегментами
;Укажем соответствие сегментных регистров сегментам
assume CS:code,DS:data
;Опишем сегмент команд
code segment ;Откроем сегмент команд
begin: mov AX,data ;Настроим DS
mov DS,AX ;на сегмент данных;
Выведем на экран строку текста
mov АН,09h ;Функция DOS вывода на экран
mov DX,offset msg ;Адрес выводимой строки
int 21h ;Вызов DOS
;Завершим программу
mov AX,4C00h ;Функция DOS завершения программы
int 21h ;Вызов DOS
code ends ;Закроем сегмент команд
;Опишем сегмент данных
data segment ;Откроем сегмент данных
msg db "Программа работает!$' ;Выводимая строка
data ends ;Закроем сегмент данных
;Опишем сегмент стека
stk segment stack ;Откроем сегмент стека
db 256 dup (?) ;Отводим под стек 256 байт
stk ends ;Закроем сегмент стека
end begin ;Конец текста с точкой входа
Следует заметить, что при
вводе исходного текста программы с клавиатуры можно использовать как прописные,
так и строчные буквы; транслятор воспринимает, например, строки MOV AX,DATA
и mov ax.data одинаково. Однако с помощью соответствующих ключей можно заставить
транслятор различать прописные и строчные буквы в отдельных элементах предложений.
В настоящей книге в текстах программ и при описании операторов языка в основном
используются строчные буквы, за исключением обозначений регистров, которые для
наглядности выделены прописными буквами.
Предложения языка ассемблера могут содержать комментарии, которые отделяются
от предложения языка знаком точки с запятой (;). При необходимости комментарий
может занимать целую строку (тоже, естественно, начинающуюся со знака ";").
Поскольку в языке ассемблера нет знака завершения комментария, комментарий нельзя
вставлять внутрь предложения языка, как это допустимо делать во многих языках
высокого уровня. Каждое предложение языка ассемблера, даже самое короткое, должно
занимать отдельную строку текста.
В программе 1-1 описаны три сегмента: сегмент команд с именем code, сегмент
данных с именем data и сегмент стека с именем stk. Описание каждого сегмента
начинается с ключевого слова segment, предваряемого некоторым именем, и заканчивается
ключевым словом end, перед которым указывается то же имя, чтобы транслятор знал,
какой именно сегмент мы хотим закончить. Имена сегментов выбираются вполне произвольно.
Текст программы заканчивается директивой ассемблера end, завершающей трансляцию.
В качества операнда этой директивы указывается точка входа в программу; в нашем
случае это метка begin.
Порядок описания сегментов в программе, как правило, не имеет значения. Часто
программу начинают с сегмента данных, это несколько облегчает чтение программы,
и в некоторых случаях устраняет возможные неоднозначности в интерпретации команд,
ссылающиеся на данные, которые еще не описаны. Мы в начале программы расположили
сегмент команд, за ним - сегмент данных и в конце - сегмент стека; такой порядок
предоставляет некоторые удобства при отладке программы. Важно только понимать,
что в оперативную память компьютера сегменты попадут в том же порядке, в каком
они описаны в программе (если специальными средствами ассемблера не задать иной
порядок загрузки сегментов в память).
Сегменты вводятся в программу с помощью директив ассемблера segment и ends.
Что такое директива ассемблера? В тексте программы встречаются ключевые слова
двух типов: команды процессора (mov, int) и директивы транслятора (в данном
случае термины "транслятор" и "ассемблер" являются синонимами,
обозначая программу, преобразующую исходный текст, написанный на языке ассемблера,
в коды, которые будут при выполнении программы восприниматься процессором).
К директивам ассемблера относятся обозначения начала и конца сегментов segment
и ends; ключевые слова, описывающие тип используемых данных (db, dup); специальные
описатели сегментов вроде stack и т. д. Директивы служат для передачи транслятору
служебной информации, которой он пользуется в процессе трансляции программы.
Однако в состав выполнимой программы, состоящей из машинных кодов, эти строки
не попадут, так как процессору, выполняющему программу, они не нужны. Другими
словами, операторы типа segment и ends не транслируются в машинные коды, а используются
лишь самим ассемблером на этапе трансляции программы. С этим вопросом мы еще
столкнемся при рассмотрении листингов программ.
Еще одна директива ассемблера используется в первом предложении программы:
assume CS:code,DS:data
Здесь устанавливается соответствие сегмента code сегментному регистру CS и сегмента
data сегментному регистру DS. Первое объявление говорит о том, что сегмент code
является сегментом команд, и встречающиеся в этом сегменте метки принадлежат
именно этому сегменту, что помогает ассемблеру правильно транслировать команды
переходов. В нашей программе меток нет, и эту часть предложения можно было бы
опустить, однако в более сложных программах она необходима (при использовании
транслятора MASM эта часть объявления необходима в любой, даже самой простой
программе).
Второе объявление помогает транслятору правильно обрабатывать предложения, в
которых производится обращение к полям данных сегмента data. Выше уже отмечалось,
что для обращения к памяти процессору необходимо иметь две составляющие адреса:
сегментный адрес и смещение. Сегментный адрес всегда находится в сегментном
регистре. Однако в процессоре два сегментных регистра данных, DS и ES, и для
обращения к памяти можно использовать любой из них. Разумеется, процессор при
выполнении команды должен знать, из какого именно регистра он должен извлечь
сегментный адрес, поэтому команды обращения к памяти через регистры DS или ES
кодируются по-разному. Объявляя соответствие сегмента data регистру DS, мы предлагаем
транслятору использовать вариант кодирования через регистр DS.
Однако отсюда совсем не следует, что к моменту выполнения команды с обращением
к памяти в регистре DS будет содержаться сегментный адрес требуемого сегмента.
Более того, можно гарантировать, что нужного адреса в сегментном регистре не
будет. Директива assume влияет только на кодирование команд, но отнюдь не на
содержимое сегментных регистров. Поэтому практически любая программа должна
начинаться с предложений, в которых в сегментный регистр, используемый для адресации
к сегменту данных (как правило, это регистр DS) заносится сегментный адрес этого
сегмента. Так сделано и в нашем примере с помощью двух команд
mov AX,data ;Настроим DS
mov DS,AX ;на сегмент данных
с которых начинается наша
программа. Сначала значение имени data (т.е. адрес сегмента data) загружается
командой mov в регистр общего назначения процессора АХ, а затем из регистра
АХ переносится в регистр DS. Такая двухступенчатая операция нужна потому, что
процессор в силу некоторых особенностей своей архитектуры не может выполнить
команду непосредственной загрузки адреса в сегментный регистр. Приходится пользоваться
регистром АХ в качестве "перевалочного пункта".
Поместив в регистр DS сегментный адрес сегмента данных, мы получили возможность
обращаться к полям этого сегмента. Поскольку в программе может быть несколько
сегментов данных, операционная система не может самостоятельно определить требуемое
значение DS, и инициализировать его приходится "вручную".
Назначением программы 1-1 предполагается вывод на экран текстовой строки "Программа
работает!", описанной в сегменте данных. Следующие предложения программы
как раз и выполняют эту операцию. Делается это не непосредственно, а путем обращения
к служебным программам операционной системы MS-DOS, которую мы для краткости
будем в дальнейшем называть просто DOS. Дело в том, что в составе команд процессора
и, соответственно, операторов языка ассемблера нет команд вывода данных на экран
(как и команд ввода с клавиатуры, записи в файл на диске и т.д.). Вывод даже
одного символа на экран в действительности представляет собой довольно сложную
операцию, для выполнения которой требуется длинная последовательность команд
процессора. Конечно, эту последовательность команд можно было бы включить в
нашу программу, однако гораздо проще обратиться за помощью к операционной системе.
В состав DOS входит большое количество программ, осуществляющих стандартные
и часто требуемые функции - вывод на экран и ввод с клавиатуры, запись в файл
и чтение из файла, чтение или установка текущего времени, выделение или освобождение
памяти и многие другие.
Для того, чтобы обратиться к DOS, надо загрузить в регистр общего назначения
АН номер требуемой функции, в другие регистры - исходные данные для выполнения
этой функции, после чего выполнить команду hit 21h (int - от interrupt, прерывание),
которая передаст управление DOS. Вывод на экран строки текста можно осуществить
функцией 09h, которая требует, чтобы в регистрах DS:DX содержался полный адрес
выводимой строки. Регистр DS мы уже инициализировали, осталось поместить в регистр
DX относительный адрес строки, который ассоциируется с именем поля данных msg.
Длину выводимой строки указывать нет необходимости, так как функция 09h DOS
выводит на экран строку от указанного адреса до символа доллара, который мы
предусмотрительно включили в выводимую строку. Заполнив все требуемые для конкретной
функции регистры, можно выполнить команду int 21h, которая осуществит вызов
DOS.
Как завершить выполняемую программу? В действительности завершение программы
- это довольно сложная последовательность операций, в которую входит, в частности,
освобождение памяти, занятой завершившейся программой, а также вызов той системной
программы (конкретно - командного процессора COMMAND.COM), которая выведет на
экран запрос DOS, и будет ожидать ввода следующих команд оператора. Все эти
действия выполняет функция DOS с номером 4Ch. Эта функция предполагает, что
в регистре AL находится код завершения нашей программы, который она передаст
DOS. Если программа завершилась успешно, код завершения должен быть равен 0,
поэтому мы в одном предложении mov AX,4C00h загружаем в АН 4Ch, а в AL - 0,
и вызываем D'OS уже знакомой нам командой int 21h.
Для того, чтобы выполнить пробный прогон приведенной программы, ее необходимо
сначала оттранслировать и скомпоновать. Пусть исходный текст программы хранится
в файле с именем P.ASM. Трансляция осуществляется вызовом ассемблера TASM.EXE
с помощью следующей .команды DOS;
tasm /z/zi/n p/p,p
Ключ /z разрешает вывод
на экран строк исходного текста программы, в которых ассемблер обнаружил ошибки
(без этого ключа поиск ошибок пришлось бы проводить по листингу трансляции).
Ключ /zi управляет включением в объектный файл информации, не требуемой при
выполнении программы, но используемой отладчиком.
Ключ /n подавляет вывод в листинг перечня символических обозначений в программе,
от чего несколько уменьшается информативность
листинга, но сокращается его размер.
Стоящие далее параметры определяют имена файлов: исходного (P.ASM), объектного
(P.OBJ) и листинга (P.LST). При желании можно в строке вызова транслятора указать
полные имена файлов с их расширениями, однако необходимости в этом нет, так
как по умолчанию транслятор использует именно указанные выше расширения.
Строка вызова компоновщика имеет следующий вид:
tlink /x/v p,p
Ключ /х подавляет образование
листинга компоновки, который обычно не нужен.
Ключ /v передает в загрузочный файл информацию, используемую отладчиком. Стоящие
далее параметры обозначают имена модулей: объектного (Р.ОЫ) и загрузочного (Р.ЕХЕ).
Поскольку при изучении этой книги вам придется написать и отладить большое количество
программ, целесообразно создать командный файл (с именем, например, А.ВАТ),
автоматизирующий выполнение однотипных операций трансляции и компоновки. Текст
командного файла в простейшем варианте может быть таким (в предположении, что
путь к каталогу с пакетом TASM был указан в параметре команды PATH):
tasm /z/zi/n p,p,p
tlink /х/v р,р
Запуск подготовленной программы
Р.ЕХЕ осуществляется командой .р.ехе или просто
При загрузке программы сегменты размещаются в памяти, как показано на рис. 1.9.
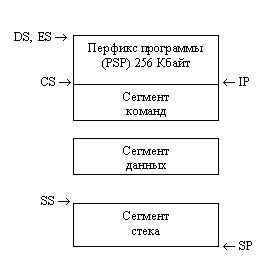
Рис. 1.9. Образ программы в памяти.
Образ программы в памяти
начинается с сегмента префикса программы (Program Segment Prefics, PSP), образуемого
и заполняемого системой. PSP всегда имеет размер 256 байт; он содержит таблицы
и поля данных, используемые системой в процессе выполнения программы. Вслед
за PSP располагаются сегменты программы в том порядке, как они объявлены в программе.
Сегментные регистры автоматически инициализируются следующим образом: ES и DS
указывают на начало PSP (что дает возможность, сохранив их содержимое, обращаться
затем в программе к PSP), CS - на начало сегмента команд, a SS - на начало сегмента
стека. В указатель команд IP загружается относительный адрес точки входа в программу
(из операнда директивы end), а в указатель стека SP - величина, равная объявленному
размеру стека, в результате чего указатель стека указывает на конец стека (точнее,
на первое слово за его пределами).
Таким образом, после загрузки программы в память адресуемыми оказываются все
сегменты, кроме сегмента данных. Инициализация регистра DS в первых строках
программы позволяет сделать адресуемым и этот сегмент.
Рисунок 1.9 еще раз подчеркивает важнейшую особенность архитектуры процессоров
Intel: адрес любой ячейки памяти состоит из двух слов, одно из которых определяет
расположение в памяти соответствующего сегмента, а другое - смещение в пределах
этого сегмента. Смысл сегментной части адреса, хранящейся всегда в одном из
сегментных регистров, в реальном и защищенном режиме различен; в МП 86 сегментная
часть адреса, после умножения ее на 16, определяет физический адрес начала сегмента
в памяти.
Отсюда следует, что сегмент всегда начинается с адреса, кратного 16, т.е. на
границе 16-байтового блока памяти (параграфа). Сегментный адрес можно рассматривать,
как номер параграфа, с которого начинается данный сегмент. Размер сегмента определяется
объемом содержащихся в нем данных, но никогда не может превышать величину 64
Кбайт, что определяется максимально возможной величиной смещения.
Сегментный адрес сегмента команд хранится в регистре CS, а смещение к адресуемому
байту - в указателе команд IP. Как уже отмечалось, после загрузки программы
в IP заносится смещение первой команды программы; процессор, считав ее из 'памяти,
увеличивает содержимое IP точно на длину этой команды (команды процессоров Intel
могут иметь длину от 1 до 6 байт), в результате чего IP указывает на вторую
команду программы. Выполнив первую команду, процессор считывает из памяти вторую,
опять увеличивая значение IP. В результате в IP всегда находится смещение очередной
команды, т. е. команды, следующей за выполняемой. Описанный алгоритм нарушается
только при выполнении команд переходов, вызовов подпрограмм и обслуживания прерываний.
Сегментный адрес сегмента данных обычно хранится в регистре DS, a смещение может
находится в одном из регистров общего назначения, например, в ВХ или SI. Однако
в МП 86 два сегментных регистра данных - DS и ES. Дополнительный сегментный
регистр ES часто используется для обращения к полям данных, не входящим в программу,
например к видеобуферу или системным ячейкам. Однако при необходимости его можно
настроить и на один из сегментов программы. В частности, если программа работает
с большим объемом данных, для них можно предусмотреть два сегмента и обращаться
к одному из них через регистр DS, а к другому - через ES.
Стеком называют область
программы для временного хранения произвольных данных. Разумеется, данные можно
сохранять и в сегменте данных, однако в этом случае для каждого сохраняемого
на время данного надо заводить отдельную именованную ячейку памяти, что увеличивает
размер программы и количество используемых имен. Удобство стека заключается
в том, что его область используется многократно, причем сохранение в стеке данных
и выборка их оттуда выполняется с помощью эффективных команд push и pop без
указания каких-либо имен.
Стек традиционно используется, например, для сохранения содержимого регистров,
используемых программой, перед вызовом подпрограммы, которая, в свою очередь,
будет использовать регистры процессора "в своих личных целях". Исходное
содержимое регистров изатекается из стека после возврата из подпрограммы. Другой
распространенный прием - передача подпрограмме требуемых ею параметров через
стек. Подпрограмма, зная, в каком порядке помещены в стек параметры, может забрать
их оттуда и использовать при своем выполнении.
Отличительной особенностью стека является своеобразный порядок выборки содержащихся
в нем данных: в любой момент времени в стеке доступен только верхний элемент,
т.е. элемент, загруженный в стек последним. Выгрузка из стека верхнего элемента
делает доступным следующий элемент.
Элементы стека располагаются в области памяти, отведенной под стек, начиная
со дна стека (т.е. с его максимального адреса) по последовательно уменьшающимся
адресам. Адрес верхнего, доступного элемента хранится в регистре-указателе стека
SP. Как и любая другая область памяти программы, стек должен входить в какой-то
сегмент или образовывать отдельный сегмент. В любом случае сегментный адрес
этого сегмента помещается в сегментный регистр стека SS. Таким образом, пара
регистров SS:SP описывают адрес доступной ячейки стека: в SS хранится сегментный
адрес стека, а в SP - смещение последнего сохраненного в стеке данного (рис.
1.10, а). Обратите внимание на то, что в исходном состоянии указатель стека
SP указывает на ячейку, лежащую под дном стека и не входящую в него.
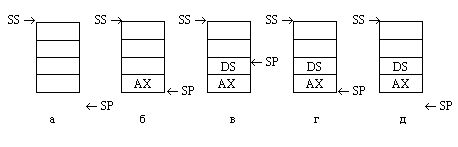
Рис. 1.10. Организация
стека:
а - исходное состояние, б - после загрузки одного элемента (в данном примере
- содержимого регистра АХ), в - после загрузки второго элемента (содержимого
регистра DS), г - после выгрузки одного элемента, д - после выгрузки двух элементов
и возврата в исходное состояние.
Загрузка в стек осуществляется специальной командой работы со стеком push (протолкнуть). Эта команда сначала уменьшает на 2 содержимое указателя стека, а затем помещает операнд по адресу в SP. Если, например, мы хотим временно сохранить в стеке содержимое регистра АХ, следует выполнить команду
push АХ
Стек переходит в состояние,
показанное на рис. 1.10, б. Видно, что указатель стека смещается на два байта
вверх (в сторону меньших адресов) и по этому адресу записывается указанный в
команде проталкивания операнд. Следующая команда загрузки в стек, например,
push DS
переведет стек в состояние,
показанное на рис. 1.10, в. В стеке будут теперь храниться два элемента, причем
доступным будет только верхний, на который указывает указатель стека SP. Если
спустя какое-то время нам понадобилось восстановить исходное содержимое сохраненных
в стеке регистров, мы должны выполнить команды выгрузки из стека pop (вытолкнуть):
pop DS
pop AX
Состояние стека после выполнения
первой команды показано на рис. 1.10, г, а после второй - на рис. 1.10, д. Для
правильного восстановления содержимого регистров выгрузка из стека должна выполняться
в порядке, строго противоположном загрузке - сначала выгружается элемент, загруженный
последним, затем предыдущий элемент и т.д.
Совсем не обязательно при восстановлении данных помещать их туда, где они были
перед сохранением. Например, можно поместить в стек содержимое DS, а извлечь
его оттуда в другой сегментный регистр - ES;
push DS
pop ES ; Теперь ES=DS, а стек пуст
Это распространенный прием
для перенесения содержимого одного регистра в другой, особенно, если второй
регистр - сегментный.
Обратите внимание (см. рис 1.10) на то, что после выгрузки сохраненных в стеке
данных они физически не стерлись, а остались в области стека на своих местах.
Правда, при "стандартной" работе со стеком они оказываются недоступными.
Действительно, поскольку указатель стека SP указывает под дно стека, стек считается
пустым; очередная команда push поместит новое данное на место сохраненного ранее
содержимого АХ, затерев его. Однако пока стек физически не затерт, сохраненными
и уже выбранными из него данными можно пользоваться, если помнить, в каком порядке
они расположены в стеке. Этот прием часто используется при работе с подпрограммами.
Какого размера должен быть стек? Это зависит от того, насколько интенсивно он
используется в программе. Если, например, планируется хранить в стеке массив
объемом 10 000 байт, то стек должен быть не меньше этого размера. При этом надо
иметь в виду, что в ряде случаев стек автоматически используется системой, в
частности, при выполнении команды прерывания int 21h. По этой команде сначала
процессор помещает в стек адрес возврата, а затем DOS отправляет туда же содержимое
регистров и другую информацию, относящуюся к прерванной программе. Поэтому,
даже если программа совсем не использует стек, он все же должен присутствовать
в программе и иметь размер не менее нескольких десятков слов. В нашем первом
примере мы отвели под стек 128 слов, что безусловно достаточно.
Система прерываний любого
компьютера является его важнейшей частью, позволяющей быстро реагировать на
события, обработка которых должна выполнятся немедленно: сигналы от машинных
таймеров, нажатия клавиш клавиатуры или мыши, сбои памяти и пр. Рассмотрим в
общих чертах компоненты этой системы.
Сигналы аппаратных прерываний, возникающие в устройствах, входящих в состав
компьютера или подключенных к нему, поступают в процессор не непосредственно,
а через два контроллера прерываний, один из которых называется ведущим, а второй
- ведомым (рис. 1.11)
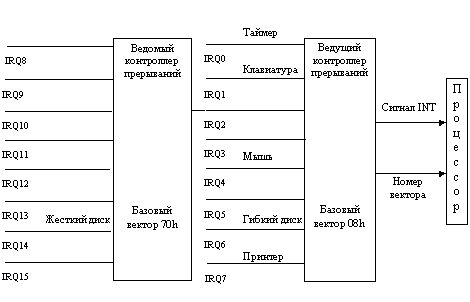
Рис. 1.11. Аппаратная организация прерываний.
Два контроллера используются
для увеличения допустимого количества внешних устройств. Дело в том, что каждый
контроллер прерываний может обслуживать сигналы лишь от 8 устройств. Для обслуживания
большего количества устройств контроллеры можно объединять, образуя из них веерообразную
структуру. В современных машинах устанавливают два контроллера, увеличивая тем
самым возможное число входных устройств до 15 (7 у ведущего и 8 у ведомого контроллеров).
К входным выводам IRQ1...IRQ7 и IRQ8...IRQ15 (IRQ - это сокращение от Interrupt
Request, запрос прерывания) подключаются выводы устройств, на которых возникают
сигналы прерываний. Выход ведущего контроллера подключается к входу INT микропроцессора,
а выход ведомого - к входу IRQ2 ведущего. Основная функция контроллеров - передача
сигналов запросов прерываний от внешних устройств на единственный вход прерываний
микропроцессора. При этом, кроме сигнала INT, контроллеры передают в микропроцессор
по линиям данных номер вектора, который образуется в контроллере путем сложения
базового номера, записанного в одном из его регистров, с номером входной линии,
по которой поступил запрос прерывания. Номера базовых векторов заносятся в контроллеры
автоматически в процессе начальной загрузки компьютера. Для ведущего контроллера
базовый вектор всегда равен 8, для ведомого - 70h. Таким образом, номера векторов,
закрепленных за аппаратными прерываниями, лежат в диапазонах 8h...Fh и 70h...77h.
Очевидно, что номера векторов аппаратных прерываний однозначно связаны с номерами
линий, или уровнями IRQ, а через них - с конкретными устройствами компьютера.
На рис. 1.11 указаны некоторые из стандартных устройств компьютера, работающих
в режиме прерываний.
Процессор, получив сигнал прерывания, выполняет последовательность стандартных
действий, обычно называемых процедурой прерывания. Подчеркнем, что здесь идет
речь лишь о реакции самого процессора на сигналы прерываний, а не об алгоритмах
обработки прерываний, предусматриваемых пользователем в программах обработки
прерываний.
Объекты вычислительной системы, принимающие участие в процедуре прерывания,
и их взаимодействие показаны на рис. 1.12.
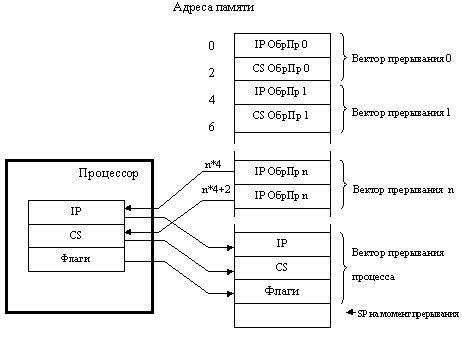
Рис. 1.12. Процедура обслуживания прерывания.
Самое начало оперативной
памяти от адреса 0000h до 03FFh отводится под векторы прерываний - четырехбайтовые
области, в которых хранятся адреса обработчиков прерываний (ОбрПр на рис. 1.12).
В два старшие байта каждого вектора записывается сегментный адрес обработчика,
в два младшие - смещение (относительный адрес) точки входа в обработчик. Векторы,
как и соответствующие им прерывания, имеют номера, причем вектор с номером 0
располагается, начиная с адреса 0, вектор 1 - с адреса 4, вектор 2 - с адреса
8 и т.д. Вектор с номером п занимает, таким образом, байты памяти от n*4 до
n*4+3. Всего в выделенной под векторы области памяти помещается 256 векторов.
Получив сигнал на выполнение процедуры прерывания с определенным номером, процессор
сохраняет в стеке выполняемой программы текущее содержимое трех регистров процессора:
регистра флагов, CS и IP. Два последних числа образуют полный адрес возврата
в прерванную программу. Далее процессор загружает CS и IP из соответствующего
вектора прерываний, осуществляя, тем самым, переход на обработчик прерывания,
связанный с этим вектором.
Обработчик прерываний всегда заканчивается командой iret (interrupt return,
возврат из прерывания), выполняющей обратные действия - извлечение из стека
сохраненных там слов и помещение их назад в регистры IP и CS, а также в регистр
флагов. Это приводит к возврату в основную программу в ту самую точку, где она
была прервана.
В действительности запросы на обработку прерываний могут иметь различную природу.
Помимо описанных выше аппаратных прерывания от периферийных устройств, называемых
часто внешними, имеются еще два типа прерываний: внутренние и программные.
Внутренние прерывания возбуждаются цепями самого процессора при возникновении
одной из специально оговоренных ситуаций, например, при выполнении операции
деления на ноль или при попытке выполнить несуществующую команду. За каждым
из таких прерываний закреплен определенный вектор, номер которого известен процессору.
Например, за делением на 0 закреплен вектор 0, а за неправильной командой -
вектор 6. Если процессор сталкивается с одной из таких ситуаций, он выполняет
описанную выше процедуру прерывания, используя закрепленный за этой ситуацией
вектор прерывания.
Наконец, еще одним чрезвычайно важным типом прерываний являются программные
прерывания. Они вызываются командой hit с числовым аргументом, который рассматривается
процессором, как номер вектора прерывания. Если в программе встречается, например,
команда
int 13h
то процессор выполняет
ту же процедуру прерывания, используя в качестве номера вектора операнд команды
int. Программные прерывания применяются в первую очередь для вызова системных
обслуживающих программ - функций DOS и BIOS. С командой int 2In вызова DOS мы
уже сталкивались в примере 1-1 и будем встречаться еще многократно. В дальнейшем
будут также приведены примеры использования команды int для вызова прикладных
обработчиков программных прерываний.
Важно подчеркнуть, что описанные действия процессора выполняются совершенно
одинаково для всех видов прерываний - внутренних, аппаратных и программных,
хотя причины, возбуждающие процедуру прерывания, имеют принципиально разную
природу.
Большая часть векторов прерываний зарезервирована для выполнения определенных
действий; часть из них автоматически заполняется адресами системных программ
при загрузке системы. Приведем краткую выдержку из таблицы векторов, позволяющую
продемонстрировать разнообразие ее состава:
00h -внутреннее прерывание,
деление на 0;
0lh -внутреннее прерывание, пошаговое выполнение (при TF=1);
02h -немаскируемое прерывание (вывод NMI процессора);
08h -аппаратное прерывание от системного таймера;
09h -аппаратное прерывание от клавиатуры;
0Eh -аппаратное прерывание от гибкого диска;
10h - программное прерывание, программы BIOS управления видеосистемой;
13h - программное прерывание, программы BIOS управления дисками;
16h - программное прерывание, программы BIOS управления клавиатурой;
IDh -не вектор, адрес таблицы видеопараметров, используемой BIOS;
lEh -не вектор, адрес таблицы параметров дискеты, используемой BIOS;
21h - программное прерывание, диспетчер функций DOS;
22h - программное прерывание, адрес перехода при завершении процесса, используемый
DOS;
23h -программное прерывание, обработчик прерываний по <Ctrl>/C, используемый
DOS;
25h - программное прерывание, абсолютное чтение диска (функция DOS);
26h - программное прерывание, абсолютная запись на диск (функция DOS);
60h...66h - зарезервировано для программных прерываний пользователя;
68h...6Fh - программные прерывания, свободные векторы;
70h -аппаратное прерывание от часов реального времени (с питанием от аккумулятора);
76h -аппаратное прерывание от жесткого диска;
Как видно из таблицы, векторы
прерываний можно условно разбить
на следующие группы:
векторы внутренних прерываний процессора (0lh, 02h и др.);
векторы аппаратных прерываний (08h...0Fh и 70h...77h);
программы BIOS обслуживания аппаратуры компьютера (10h, 13h, 16h и др.);
программы DOS (21h, 22h, 23h и др.);
адреса системных таблиц BIOS (IDh, lEh и др.).
Системные программы, адреса которых хранятся в векторах прерываний, в большинстве
своем являются всего лишь диспетчерами, открывающими доступ к большим группам
программ, реализующих системные функции. Так, видеодрайвер BIOS (вектор 10h)
включает программы смены видеорежима, управления курсором, задания цветовой
палитры, загрузки шрифтов и многие другие. Особенно характерен в этом отношении
вектор 21h, через который осуществляется вызов практически всех функций DOS:
ввода с клавиатуры и вывода на экран, обслуживания файлов, каталогов и дисков,
управления памятью и процессами, службы времени и т.д. Для вызова требуемой
функции надо не только выполнить команду int с соответствующим номером, но и
указать системе в одном из регистров (для этой цели всегда используется регистр
АН) номер вызываемой функции. Иногда для "многофункциональных" функций
приходится указывать еще и номер подфункции (в регистре AL).
Система ввода-вывода, т.
е. комплекс средств обмена информацией с внешними устройствами, является важнейшей
частью архитектуры процессора и машины в целом. К системе ввода-вывода можно
отнести и способы подключения к системной шине различного оборудования, и процедуры
взаимодействия процессора с этим оборудованием, и команды процессора, предназначенные
для обмена данными с внешними устройствами.
Непрерывное совершенствование микропроцессоров и стремление максимально повысить
производительность всей вычислительной системы привело к существенному усложнению
внутренней организации компьютеров: повышению разрядности шин, появлению внутренних
быстродействующих магистралей обмена данными, использованию кэш-буферов для
ускорения обмена с памятью и дисками и проч. Если, однако, отвлечься от важных
с точки зрения производительности, но несущественных для программиста деталей,
то логическую схему современного компьютера можно представить традиционным образом,
в виде системной шины (магистрали), к которой подключаются сам микропроцессор
и все устройства компьютера (рис. 1.13).
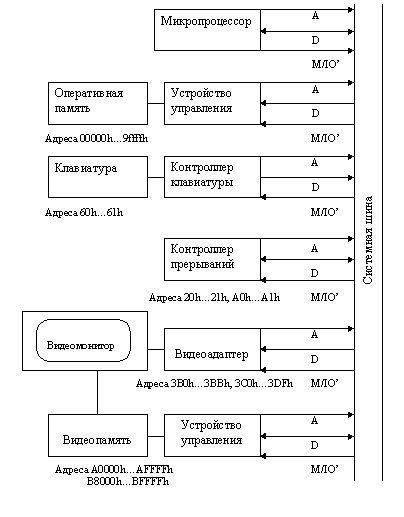
Рис. 1.13. Подключение устройств компьютера к системной шине(A - адреса; D - данные; M/IO - один из сигналов управления)
Системная шина представляет
собой, в сущности, набор линий - проводов, к которым единообразно подключаются
все устройства компьютера. В более широком плане в понятие системной шины следует
включить электрические и логические характеристики сигналов, действующих на
линиях шины, их назначение, а также правила взаимодействия этих сигналов при
выполнении тех или иных операций на шине - то, что обычно называют протоколами
обмена информацией. Сигналы, распространяющиеся по шине, доступны всем подключенным
к ней устройствам, и в задачу каждого устройства входит выбор предназначенных
ему сигналов и обеспечение реакции на них, соответствующей протоколу обмена.
Процессор связан с системной шиной большим количеством линий (практически всеми
своими выводами), из которых нас будут интересовать только линии трех категорий:
набор линий адресов, набор линий данных и один из сигналов управления, носящий
название М / IO' (М - "IO с отрицанием"). Последний сигнал, строго
говоря, имеется только среди выходных сигналов микропроцессора, а на системную
шину приходят производные от этого сигнала, образованные, как комбинации сигнала
М / IO' с управляющими сигналами записи и чтения. Однако суть дела от этого
не изменяется, и для простоты мы опустили эти подробности.
Процессор, желая записать данное по некоторому адресу в памяти, выставляет на
линии адресов требуемый адрес, а на линии данных - данное. Устройство управления
памятью расшифровывает поступивший адрес и, если этот адрес принадлежит памяти,
принимает с линий данных поступившее данное и заносит его в соответствующую
ячейку памяти. Описанная процедура отражает выполнение процессором команды типа
mov mem,AX
где mem - символическое
обозначение ячейки памяти, принадлежащей сегменту данных программы.
Если процессор, выполняя команду типа
mov AX, mem
должен прочитать данное
из памяти, он выставляет на линии адресов требуемый адрес и ожидает поступления
данных. Устройство управления памятью, расшифровав поступивший адрес и убедившись
в наличии такого адреса в памяти, отыскивает в памяти требуемую ячейку, считывает
из нее данное и выставляет его на линии данных. Процессор снимает данное с шины
и отправляет его в указанный в команде операнд (в данном случае в регистр АХ).
Описанные процедуры записи и чтения справедливы не только по отношении к памяти;
для всех остальных устройств компьютера они выглядят точно так же. За каждым
устройством закреплена определенная группа адресов, на которые оно должно отзываться.
Обнаружив свой адрес на магистрали, устройство, в зависимости от заданного процессором
направления передачи данных, либо считывает с магистрали поступившие данные,
либо, наоборот, устанавливает имеющиеся в нем данные на магистраль.
Из рис. 1.13 видно, что все устройства компьютера можно разбить на две категории.
Представителем одной категории является видеобуфер, входящий в видеосистему
компьютера. Устройство управления видеобуфером настроено на две группы адресов,
которые как бы продолжают адреса, относящиеся к оперативной памяти. Действительно,
адрес последнего байта оперативной памяти составляет 9FFFFh, а уже следующий
адрес A0000h является адресом первого байта графического видеобуфера. Графический
видеобуфер занимает 64 Кбайт адресного пространства до адреса AFFFFh (реально
немного меньше, но в плане рассматриваемого вопроса это не имеет значения).
Текстовый видеобуфер расположен на некотором расстоянии от графического и занимает
32 Кбайт, начиная с адреса B8000h. Таким образом, адреса оперативной памяти
и памяти видеобуфера разнесены и не перекрываются.
Ко второй категории устройств можно отнести все устройства, адреса которых перекрываются
с адресами оперативной памяти. Например, за контроллером клавиатуры закреплены
два адреса: 60h и 61h. По адресу 60h выполняется чтение кода нажатой клавиши,
а адрес 61h используется для управления работой контроллера. И тот, и другой
адрес имеются в оперативной памяти и, таким образом, возникает проблема распознавания
устройства, к которому происходит обращение. Аналогичная ситуация наблюдается
и со многими другими устройствами компьютера. Например, контроллер прерываний,
служащий для объединения сигналов прерываний от всех устройств компьютера и
направления их на единственный вход прерывания микропроцессора, управляется
через два адреса Поскольку -в состав машины всегда включают два контроллера,
для них выделяются две пары адресов. Во всех компьютерах типа IBM PC контроллерам
прерываний назначаются адреса 20h-21h и A0h-Alh, которые так же отвечают и некоторым
байтам оперативной памяти.
Проблема идентификации устройств с перекрывающимися адресами имеет два аспекта:
аппаратный и программный. Идентификация устройств на системной шине осуществляется
с помощью сигнала М / IO', которой генерируется процессором в любой операции
записи или чтения. Однако значение этого сигнала зависит от категории адресуемого
устройства. При обращении к памяти или видеобуферу процессор устанавливает значение
сигнала М / IO' = 1 (М обозначает memory, память). При обращении к остальным
устройствам этот сигнал устанавливается в О (IO обозначает in-out, ввод-вывод,
и если IO с отрицанием равно 0, то IO равно 1, и это олицетворяет не операцию
с памятью, а операцию ввода-вывода). В то же время все устройства, подключенные
к шине, анализируют значение сигнала М / IO1. При этом память и видеобуфер отзываются
на операции чтения-записи на шине, только если они сопровождаются значением
М / IO' = 1, а остальные устройства воспринимают сигналы магистрали только при
значении М / IO' = 0. Таким образом осуществляется аппаратное разделение устройств
"типа памяти" и устройств "ввода-вывода".
Программное разделение устройств реализуется с помощью двух наборов команд процессора
- для памяти и для устройств ввода-вывода. В первую группу команд входят практически
все команды процессора, с помощью которых можно обратиться по тому или иному
адресу - команды пересылки mov и movs, арифметических действий add, mul и div,
сдвигов rol, ror, sal и sar, анализа содержимого байта или слова test и многие
другие. Фактически в эту группу команды входит большинство команд процессора.
Вторую группу команд образуют специфические команды ввода-вывода. В МП 86 их
всего две - команда ввода in и команда вывода out. При выполнении команд первой
группы процессор автоматически генерирует М / IO' = 1; при выполнении команд
in и out процессор устанавливает сигнал М / IO' = 0.
Таким образом, при обращении к памяти и к видеобуферу программист может использовать
все подходящие по смыслу команды процессора, при этом, работая, например, с
видеобуфером, можно не только засылать в него (или получать из него) данные,
но и выполнять прямо в видеобуфере любые арифметические, логические и прочие
операции.
Обращаться же к контроллерам тех или иных устройств (и, между прочим, к видеоадаптеру),
допустимо только с помощью двух команд - in и out. Арифметические операции или
анализ данных в устройстве невозможен. Необходимо сначала прочитать в процессор
данное из внешнего устройства, и лишь затем выполнять над ним требуемую операцию.
Наличие двух категорий адресов устройств дает основание говорить о существовании
двух адресных пространств - пространства памяти, куда входит сама память, а
также видеобуферы и ПЗУ, и пространства ввода-вывода (пространства портов),
куда входят адреса остальной аппаратуры компьютера. При этом, если объем адресного
пространства памяти составляет 1 Мбайт (а в защищенном режиме 4 Гбайт), то адресное
пространство портов гораздо меньше - его размер составляет всего 64 Кбайт. Эта
величина определяется форматом команд ввода-вывода. Адрес адресуемого порта
должен быть записан в регистр DX (и ни в какой другой) и, таким образом, максимальное
значение этого адреса составляет величину FFFFh. Реально из 64 Кбайт адресного
пространства портов используется лишь очень малая часть. Практические вопросы
программирования через общее с памятью адресное пространства и через пространство
портов будут рассмотрены в следующих главах.