АЛГОРИТМЫ
Новости
Рассылка новостей
Форум
AlgoPascal
Редактор блок-схем
Статьи
О сайте
Контакты
Обзор поисковых методов.
Автор: Бойцов Леонид
Сайт по нечеткому поиску.
Обзор поисковых методов.
Наиболее распространенные в настоящее время методы поиска, используемые информационно-поисковыми системами (ИПС), можно разделить на две группы:
- поиск по ключевым словам (терминам)
- кластерные методы
В первую группу попадает, по-видимому, абсолютное большинство современных ИПС, в том числе и ПС, которые обрабатывают запросы на естественных языках (Яндекс, Yahoo, и.т.д.). В процессе поиска такие системы, как правило, производят выборку всех документов, содержащих хотя бы одно ключевое слово (грамматическую форму данного слова или синонима), а затем ранжируют эти документы по убыванию степени соответствия (релевантности) поисковому запросу.
Кластерные методы основаны на следующем наблюдении: близкие в смысле значения функции соответствия документы обычно выбираются одинаковыми поисковым запросам. Таким образом, разбив все документы на группы или кластеры и построив в каждой группе характерного представителя: центроид кластера, можно сравнивать запрос не с каждым документом по отдельности, а сначала только с центроидами. Если центроид релевантен запросу, то нужно продолжать поиск внутри кластера, нет - перейти к рассмотрению другого кластера.
Поиск по ключевым словам (терминам). Обратимся к более подробному описанию поиска по ключевым словам. Будучи весьма эффективным и легко реализуемым, он получил наибольшее распространение. Для поиска по ключевым словам используют, в основном, индексы следующих двух типов:
- инвертированные файлы (ИФ) [1,3,4,7]
- сигнатурные файлы (СФ) [3,4,7].
ИФ являются аналогом предметного указателя в конце книги. ИФ - это множество пар: ключевое слово, адрес вхождения ключевого слова в документ. Детализация адреса термина бывает различной: вхождение слова может быть задано на уровне документа, абзаца, или даже на уровне точного местоположения в тексте. Основным недостатком ИФ является его большой объем. Если не применять специальные методы кодирования списков вхождений, то размер ИФ может превышать размер информационного массива документов в 2-3 раза.
СФ разрабатывались как альтернативный по отношению к ИФ с более компактным индексом. Размер СФ составляет около 50% от размера исходных данных. В настоящее время разработаны методы кодирования [4], позволяющие строить компактные ИФ, поэтому СФ применяются не очень часто.
Рассмотрим типы запросов в ИПС. Типы поисковых выражений можно классифицировать по нескольким параметрам. Прежде всего, можно выделить контекстно-зависимые и контекстно-независимые запросы. В случае контекстно-независимых запросов предполагается, что документ состоит из некоторых неделимых компонентов: в большинстве случаев, слов. Контекстно-зависимые запросы могут быть очень разнообразны, начиная с поиска подстроки в документе, и заканчивая условием на наличие определенных ключевых слов в одном предложении, абзаце, и.т.д.
Язык задания поискового запроса может быть, как формальным (булевым), так и естественным. По этому признаку запросы можно разделить на булевы или логические и ранжированные.
В случае булева поиска пользователь задает условие вхождения ключевых слов в документ в виде булевской функции. При поиске по ранжированным запросам текст запроса обычно записывается на естественном языке. ИПС разбирает запрос, выделяя в нем слова, или устойчивые выражения, расширяет запрос синонимами терминов поискового запроса и производит поиск всех документов, содержащих хотя бы один термин. Найденные документы ранжируются по степени релевантности запросу.
Возможны различные варианты сопоставления ключевых слов запроса и документа:
- точное соответствие.
- с учетом изменяемости слова.
- по сходству.
Название первого пункта говорит само за себя: при поиске на точное равенство ищутся только те документы, в которые ключевое слово входит точно в той форме, которую указал в запросе пользователь.
К сожалению, поиск на точное соответствие не позволяет найти слово, если в документе оно встречается в другой грамматической форме, поэтому большинство ИПС осуществляет поиск с учетом изменяемости слова. Современные системы также отождествляют такие слова как делать и дело, осуществляя поиск по словоформе. Поиск по словоформе и поиск с учетом изменяемости слова являются одним из вариантов поиска по сходству, учитывающим только определенный тип ошибок.
В электронных документах бывают орфографические ошибки да и сам пользователь не всегда набирает термины запроса правильно, поэтому ИПС должна "уметь" находить достаточно "похожие" слова. Ключевым моментом поиска по сходству является выбор меры степени "похожести". Я буду использовать метрику (функцию) Левенштайна, которую также часто называют расстоянием редактирования. Расстояние Левенштайна между словами u и v равно минимальному количеству операций редактирования, необходимых для преобразования u в v.
Выбор в качестве меры близости метрики Левенштайна обусловлен двумя факторами. Во-первых, расстояние Левенштайна формализует интуитивное понятие об "ошибке", а во-вторых, существует множество алгоритмов эффективного его вычисления [2,6,8,13,14,17]. Фактически, при поиске требуется не столько значение расстояния между строками u и v, сколько знание превышает ли L(u,v) некоторое наперед заданное пороговое значение.
Тестирование программы agrep [13,14] показывает, что время, затрачиваемое на сравнение слов, на порядок меньше времени считывания с диска, в том числе, при поиске по сходству. Таким образом, оптимизация поиска по сходству почти напрямую зависит от сокращения объема дисковых операций.
Для поиска на неточное равенство также целесообразно использовать ИФ. Правда, при этом в словаре нужно обязательно хранить все без исключения термины, встречающиеся в документах. Следует отметить, что в контексте нечеткого поиска в инвертированном файле одним из самых важных моментов является индексация словаря, потому что поиск по сходству требует больших временных затрат.
Обзор методов поиска по сходству в словаре.
В настоящее время для поиска термина в словаре применяют, в основном, следующие методы:
- полный перебор всех терминов словаря, или последовательный поиск.
- метод расширения выборки, или метод спел-чекера.
- метод n-грам (триад).
- trie-деревья.
- триангуляционные деревья.
Полный перебор. Данный метод осуществляет последовательное считывание данных с диска и сравнение с термином запроса. Основным достоинством этого метода является простота реализации и, как это ни странно, довольно высокая скорость работы. Дело в том, что при последовательном считывании больших файлов (при условии невысокой фрагментации на диске) достигается пиковая скорость чтения. Кроме того, этот метод позволяет реализовать многофункциональный поиск, например, по подстроке или регулярным выражениям, без каких-либо существенных ограничений.
Метод расширения выборки. Суть данного метода заключается в следующем: строится множество всевозможных "ошибочных" слов, например, получающихся из исходного в результате одной операции редактирования, после чего построенные термины ищутся в словаре (на точное соответствие).
Метод n-грам. Идея этого метода заключается в следующем: если строка v "похожа" на строку u, то у них должны быть какие-либо общие подстроки. Поэтому бывает целесообразно строить инвертированный файл, в котором роль документов играют сами термины, а роль терминов - подстроки длины n, называемые также n-грамами. Основной недостаток метода n-грам - большой размер файла.
Trie-деревья. В отличии от обычных сбалансированных деревьев, в trie-дереве все строки, имеющие общее начало, располагаются в одном поддереве. Каждое ребро помечено некоторой строкой. Терминальным вершинам ("листьям") соответствуют слова списка.
Пусть список строк содержит термины: дерево, деревья, пол, половик; тогда соответствующее ему trie-дерево изображено на рис. 1:
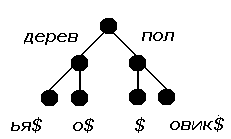 |
| Рис 1. |
Чтобы ни одно из слов не было префиксом другого слова (как в случае слов пол и половик), в конец каждого слова добавляется специальный символ $, отсутствующий в алфавите.
Обычно trie-деревья используются для поиска по подстроке, но их можно использовать, и весьма эффективно, для поиска по сходству [13]. Чтобы обеспечить поиск по подстроке, необходимо хранить в trie-дереве все суффиксы (или префиксы терминов). При этом, как и в случае метода n-грам размер индекса в 2-10 раз превышает размер словаря.
Триангуляционные деревья. Триангуляционные деревья [18] позволяют индексировать множества произвольной структуры, при условии, что на них задана метрика. Существует довольно много различных модификаций этого метода, но все они не слишком эффективны в случае текстового поиска и чаще используются для организации поиска в базе данных изображений или других сложных объектов.
Литература.
1. Э. Озкарахан, Машины баз данных и управление базами данных, М. Мир 1989.
2. A. Ehrenfeucht, D. Haussler. A New Distance Metric on Strings Computable in Linear Time. Discrete Applied Mathematics, 20:191-203, 1988.
3. Christos Faloutsos and Douglas Oard, Survery of Information Retrieval and Filtering Methods, University of Maryland.
4. J. Zobel and A. Moffat and K. Ramamohanarao, Inverted files versus signature files for text indexing, Collaborative Information Technology Research Institute, Departments of Computer Science, RMIT and The University of Melbourne, Australia, feb 1995, Technical report No TR-95-5
5. Hugh E. Williams and Justin Zobel, Compressing Integers for Fast File Access, Computer Journal, Volume 42, Issue 03, pp. 193-201.
6. U. Masek, M. S. Peterson. A faster algorithm for computing string-edit distances. Journal of Computer and System Sciences, 20(1), 785-807,1980.
7. C.J. van Rijsbergen, Information Retrieval, London: Butterworths, 1979
8. P.H. Sellers, The Theory of Computation of Evolutionary Distances: Pattern recognition. Journal of Algorithms, 1:359-373, 1980.
9. E. Ukkonen, Algorithms for approximate string matching, 1985, Information and Control, 64, 100-118.
10. E. Ukkonen, Finding approximate patterns in strings, O(k x n) time. Journal of Algorithms 1985, 6 , 132-137.
11. E. Ukkonen, Approximate String Matching with q-Grams and maximal matches. Theoretical Computer Science, 92(1), 191-211,1992.
12. E. Ukkonen, Approximate String Matching over Suffix-Trees. In Proceedings of the Fourth Annual Symposium on Combinatorial Pattern Matching, Padova, Italy, June, pp. 229-242, 1993.
13. H. Shang & T. H. Merrett, 1996 Tries for Approximate String Matching IEEE Trans. on Knowledge and Data Engineering, special issue on Digital Libraries, Nabil R. Adam, ed., 8 4(August, 1996) pp. 540--7
14. Wu S. and U. Manber, Agrep - A Fast Approximate Pattern-Matching Tool, Usenix Winter 1992. Technical Conference, San Francisco (January 1992), pp.153-162.
15. U. Manber, A text compression scheme that allows fast searching directly in the compressed file, in Combinatorial Pattern Matching. 5th Annual Symposium, CPM 94. Proceedings, p. 113-24. Asilomar, CA, USA, 5-8 June 1994.
16. Wu S., U. Manber, GLIMPSE: A Tool to Search Through Entire File Systems, Winter USENIX Technical Conference, 1994.
17. R.A. Wagner and M.J. Fisher, The String to String Correction Problem. Journal of the ACM, 21(1):168-173, 1974.
18. Ricardo Baeza-Yates, Gonzalo Navarro, Fast Approximate Matching in a Dictionary. In 5th South American Symposium on String Processing and Information Retrieval (SPIRE'98), Sta. Cruz de la Sierra, Bolivia, September 1998. IEEE CS Press.
19. R. Baeza-Yates and G. Navarro, Journal of the American Society on Information Systems 51 (1), 69-82, Jan 2000.
Бочканов Сергей, Быстрицкий Владимир
Copyright © 1999-2004
При поддержке проекта MANUAL.RU