 |

Поиск в строках, массивах, последовательностях:
Общие подпоследовательности, дистанция.
Метод динамического программирования Вагнера и Фишера.
В методе динамического программирования последовательно, по предыдущим значениям, вычисляются расстояния между все более и более длинными префиксами двух строк – до получения окончательного результата. Опишем этот процесс более подробно.
Пусть di,j есть расстояние между префиксами строк x и y, длины которых равны, соответственно, i и j, то есть
| (9) |
Цену преобразования символа a в символ b обозначим через w(a,b). Таким образом, w(a,b) – это цена замены одного символа на другой, когда a =/= b, w(a,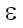 ) – цена удаления a, а w(, b) – цена вставки b. Заметим, что в случае, когда выполнены нижеследующие условия, d является расстоянием Левенштейна:
) – цена удаления a, а w(, b) – цена вставки b. Заметим, что в случае, когда выполнены нижеследующие условия, d является расстоянием Левенштейна:
| ) = 1
w( , b) = 1
w(a, b) = 1, если a =/=b, w(a, b) = 0, если a=b |
|
В процессе вычислений значения di,j записываются в массив (m+1) * (n+1), а вычисляются они с помощью следующего рекуррентного соотношения.
|
), di,j-1 + w(, yj), di-1,j-1 + w(xi, yi)}
|
(11) |
Оно выводится следующим образом. Если предположить, что известна цена преобразования x(1, i-1) в y(1, j), то цену преобразования x(1, i) в y(1,j) мы получим, добавив к ней цену удаления xi. Аналогично, цену преобразования x(1, i) в y(1, j) можно получить, прибавив цену вставки yj к цене преобразования x(1, i) в y(1, j-1). Наконец, зная цену преобразования x(1, i-1) в y(1, j-1), цену преобразования x(1, i) в y(1, j) мы получим, прибавив к ней цену замены xi на yj. Вспомним, что расстояние di,j является минимальной ценой преобразования x(1,j) в y(1,j), поэтому из трех указанных выше операций надо выбрать самую дешевую.
Перед тем, как начать вычислять di,j, надо установить граничные значения массива. Что касается первого столбца массива, то значение di,0 равно сумме цен удаления первых i символов x. Аналогично, значения d0,j первой строки задаются суммой цен вставки первых j символов y. Итак, имеем следующее:
 для 1 < i < m для 1 < i < m
 для 1 < j < n для 1 < j < n |
|
Для расстояния Левенштейна di,0 = i и d0,j = j. Ниже приведен массив, полученный при вычислении расстояния Левенштейна между строками preterit и zeitgeist. Из него видно, что расстояние между этими строками, то есть d8,9, равно 6.
|
|
j |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
i |
|
|
z |
e |
i |
t |
g |
e |
i |
s |
t |
|
0 |
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
1 |
p |
1 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
2 |
r |
2 |
2 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
3 |
e |
3 |
3 |
2 |
3 |
4 |
5 |
5 |
6 |
7 |
8 |
|
4 |
t |
4 |
4 |
3 |
3 |
3 |
4 |
5 |
6 |
7 |
7 |
|
5 |
e |
5 |
5 |
4 |
4 |
4 |
4 |
4 |
5 |
6 |
7 |
|
6 |
r |
6 |
6 |
5 |
5 |
5 |
5 |
5 |
5 |
6 |
7 |
|
7 |
i |
7 |
7 |
6 |
5 |
6 |
6 |
6 |
5 |
6 |
7 |
|
8 |
t |
8 |
8 |
7 |
6 |
5 |
6 |
7 |
6 |
6 |
6 |
Алгоритм вычисления массива расстояний, разработанный Вагнером и Фишером (Wagner, Fisher), приведен на рисунке 10. Можно видеть, что стадия инициализации границ включает 1+m+n, а основной цикл повторяется mn раз. Таким образом, временная сложность этого алгоритма есть O(mn).
- инициализация границ массива d0,0 = 0 for i = 1 to m di,0 = di-1,0 + w(xi,
Рис. 10. Вычисление расстояния между строками по Вагнеру и Фишеру
Последовательность операций редактирования для преобразования x в y можно получить с помощью структуры, называемой след. След из x в y можно описать как соединение символов строки x с символами помещенной под ней строки y ребрами, причем каждый из символов соприкасается не больше чем с одним ребром, и никакие два ребра не пересекаются. Представляя ребро из xi в yj как упорядоченной парой целых чисел (i, j), след из x в y можно формально определить как множество упорядоченных пар, удовлетворяющих следующим условиям:
| (13) | |
i1 =/=i2 и j1 =/=j2, i1 < i2<=> j1 < j2 |
Последовательность операций редактирования можно получить из следа следующим образом. Все не касающиеся ребер символы x надо удалить, а аналогичные символы y вставить. Для каждого ребра (i, j) в следе, xi заменить на yj, если xi =/=yj, если же xi = yj, то редактирование не требуется. Вернемся к предыдущему примеру: вот как выглядит след с наименьшей ценой от preterit к zeitgeist.
i 1 2 3 4 5 6 7 8
xi p r e t e r i t
| / | \ | \
yj z e i t g e i s t
j 1 2 3 4 5 6 7 8 9
След наименьшей цены, и, таким образом, последовательность операций редактирования наименьшей цены, переводящую x в y, можно получить из заполненного массива расстояний. Алгоритм для выдачи упорядоченных пар следа вы найдете на рисунке 11. Процедура начинает работу с dm,n, и идет обратно, пока оба индекса i и j больше 0. Надо определить, по которому из соседей было выведено di,j, и перейти к этой позиции в массиве. Если di,j выведено из di-1,j-1, то выходом будет упорядоченная пара (i,j), соответствующая ребру в следе, то есть замене или сопоставлению, в зависимости от того, равны xi и yj или нет. Если di,j выведено из di-1,j или di,j-1, ничего не выдается, так как удаление и вставка соответствуют символам, не соприкасающимся с ребрами. Так как при каждом проходе цикла уменьшается либо i, либо j, либо оба индекса, максимальное число итераций равно m+n. Таким образом, след наименьшей цены определяется за время O(m+n).
i = m j = n while(i > 0) and (j > 0) if di,j = di-1,j + w(xi,
Рисунок 11 Вычисление следа наименьшей цены по Вагнеру и Фишеру
Для предыдущего примера данная процедура дает следующий след T (в порядке, обратном тому, в котором эти пары выдаются алгоритмом).
T = {(1,1), (3,2), (4,4), (5,6), (7,7), (8,9)}
Теперь совершенно очевидно, как получить lcs(x,y) по следу наименьшей цены из x в y. Компонентами lcs(x, y) являются символы xi, или, что эквивалентно, символы yj, такие, что (i, j)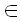 T и xi = yj. Таким образом, для нашего примера мы имеем:
T и xi = yj. Таким образом, для нашего примера мы имеем:
lcs(x, y) = x3x4x5x7x8 = y2y4y6y7y9 = eteit
И наконец, следует упомянуть, что, как указывают Вагнер и Фишер, в некоторых приложениях, скажем, при проверке правописания, может быть полезна весовая функция цены редактирования a![]() b, w(a,b), зависящая от символов a и b. Например, при стандартной клавиатуре qwerty букву e легче перепутать с w, чем с p. Согласно этому критерию wast, например, будет ближе к east чем к past.
b, w(a,b), зависящая от символов a и b. Например, при стандартной клавиатуре qwerty букву e легче перепутать с w, чем с p. Согласно этому критерию wast, например, будет ближе к east чем к past.
 Вверх по странице, к оглавлению и навигации.
Вверх по странице, к оглавлению и навигации.