 |

Cтруктуры данных. Хранение информации.
Б-деревья.
Словари для очень больших файлов располагаются, как правило, во вторичной памяти, такой, как диск. Словарь представляет собой индекс исходного файла и содержит ключи и адреса записей в нем. Для реализации словаря мы могли бы использовать красно-черные деревья, заменив указатели на смещения от начала индексного файла, и использовать обычный произвольный доступ для узлов дерева.
Однако, каждый переход по дереву означает обращение к диску и, значит, обходится достаточно дорого. Напомню, что операция доступа к диску означает посекторный обмен; типичный размер сектора - 256 байтов. Мы можем уравнять размер узла с размером сектора и сгруппировать вместе несколько ключей в каждом узле, чтобы уменьшить количество операций обмена. В этом, собственно, и состоит идея Б-деревьев. Они хорошо описаны в книжках Кнута[1998] и Кормена[1990]. О Б+-деревьях почитайте в книжке Ахо[1983].
Теория.
Б-деревьяа рис. 4-3 представлено Б-дерево с 3 ключами на узел. Ключи в внутреннем узле окружены указателями или смещениями записей, отсылающими к ключам, которые либо все больше, либо все меньше окруженного ключа. Например, все ключи, меньшие 22, адресуются левой ссылкой, все большие - правой. Для простоты здесь не показаны адреса записей, связанные с каждым ключом.
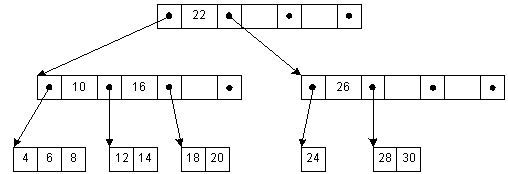
Рис. 4-3: Б-дерево
В этом двухуровневом дереве мы можем добраться до любого ключа за три доступа к диску. Если бы мы сгруппировали по 100 ключей на узел, то за три доступа к диску мы могли бы найти любой ключ из 1000000. Чтобы сохранить это свойство, нам нужно сохранять сбалансированность дерево во время вставок и удалений. Во время вставки мы исследуем потомка, чтобы определить, можно ли добавить в него узел. Если нет, в дерево добавляется еще один брат, а ключи потомка перераспределяются так, чтобы появилось место для нового узла. Когда мы спускаемся, чтобы вставить ключ, и узел оказывается заполненным, мы рассыпаем корень, у которого появляются новые потомки, так что глубина дерева увеличивается.
Аналогичные действия предпринимаются при удалении - здесь может потребоваться объединить потомков. Этот метод изменения глубины дерева позволяет сохранить сбалансированность дерева.
| Б-дерево | Б*-дерево | Б+-дерево | Б++-дерево | |
|---|---|---|---|---|
| данные хранятся в | любом узле | любом узле | только в листьях | только в листьях |
| при вставке - расщепление | 1 x 1 –>2 x 1/2 | 2 x 1 –>3 x 2/3 | 1 x 1 –>2 x 1/2 | 3 x 1 –>4 x 3/4 |
| при удалении - слияние | 2 x 1/2 –>1 x 1 | 3 x 2/3 –>2 x 1 | 2 x 1/2 –>1 x 1 | 3 x 1/2 –>2 x 3/4 |
В таблице 4-1 приведены несколько вариантов Б-деревьев. В стандартных Б-деревьях ключи и данные хранятся как во внутренних узлах, так и в листьях (концевых узлах). Если при спуске по дереву во время вставки встречен заполненный узел, его содержимое перераспределяется между братьями. Если братья тоже полны, создается новый узел и половина ключей потомка пересылается в него. Во время удаления наполовину заполненные потомки являются первыми кандидатами на добавление ключей из прилежащих узлов. Если сами прилежащие узлы полны лишь наполовину, они объединяются так, чтобы получился полный узел. Б*-деревья устроены аналогично, единственное отличие - узлы заполняются на 2/3. Это приводит к лучшему использованию места, занимаемого деревом, и чуть лучшей производительности.
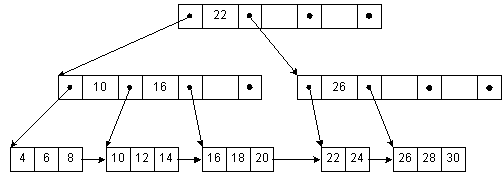
Рис. 4-4: Б+-дерево
На рис. 4-4 представлено Б+-дерево. Все ключи хранятся в листьях, там же хранится и информационная часть узла. Во внутренних узлах хранятся копии ключей - они помогают искать нужный лист. У указателей смысл немножко не такой, как при работе с обычными Б-деревьями. Левый указатель ведет к ключам, которые меньше заданного значения, правый - ключам, которые больше или равны (GE). Например, к ключам, меньшим 22, ведет левый указатель, а к ключам от 23 и выше ведет правый. Обратите внимание на то, что ключ 22 повторяется в листе, где хранятся соответствующие ему данные. Во время вставки и удаления необходимо аккуратно работать с родительскими узлами. Когда модифицируются первый ключ в листе, дерево проходится от листа к корню. Последний из GE-указателей, найденный при спуске по дереву, и является тем, который потребуется модифицировать, чтобы отразить новое значение ключа. Поскльку все ключи повторяются в листьях, мы можем связать их для последовательного доступа.
Последний метод, Б++-деревья, мое изобретение. Оно устроено аналогично Б+-деревьям, отличается лишь стратегия расщепления/объединения.
Предположим, что в каждом узле могут храниться k ключей, а в корне их может быть 3k. Перед тем, как во время вставки мы спустимся к потому, мы проверяем пуст ли он. Если это так, ключи, находящиеся в потомке и лвух смежных к нему узлах, объединяются и перераспределяются. Если два смежных узла также заполнены, то добавляется узел. Таким образом, мы получаем уже четыре узла, каждый из которых полон на 3/4. Перед тем, как во время удаления спуститься к потомку, мы проверяем, не полон ли он на 1/2. Если это так, ключи потомка и двух смежных узлов объединяются и перераспределяются. Если два смежных узла сами полны наполовину, они сливаются в два узла, каждый из которых полон на 3/4. Мы, таким образом, оказываемся посредине между заполненностью на 1/2 и полной заполненностью, что позволяет нам ожидать равного числа вставок и удалений.
Напомним, что в корневом узле хранятся 3k ключей. Если во время вставки окажется, что корень полон, мы распределяем ключи по четырем новым узлам, каждый из которых полон на 3/4. Это увеличивает высоту дерева. Во время удаления мы исследуем потомков. Если имеется только три потомка и они полны наполовину, переносим их содержимое в корень, в результате чего высота дерева уменьшается.
Другой способ описать работу с деревом - сказать, что мы собираем три узла, а затем рассыпаем их. При вставке, когда нам нужен дополнительный узел, мы рассыпаем на четыре узла. При удалении, когда узел нужно удалить, мы рассыпаем на два узла. Симметрия операций позволяет использовать при реализации вставки и удаления одни и те же собирающие/рассыпающие функции.
Реализация.
Среди сопровождающих эти заметки кодах имеется реализация Б++-деревьев на ANCI-C. В разделе, зависящем от реализации, необходимо определить bAdrType и eAdrType, которые используются для смещений - в файле Б-дерева и в файле данных соответственно. Вам понадобится также написать функцию, которая используется в алгоритмах Б++-дерева для сравнения ключей. Имеются функции, для вставки/удаления ключей, поиска ключей и для последовательного доступа к ключам. Функция main в конце файла - простой пример вставки.
В приведенных кодах допустимы множественные ссылки на одни и те же данные. Реализация использует дескриптор (handle), возвращаемый после открытия индекса. При последующем доступе работа ведется с этим дескриптором. Разрешены повторяющиеся ключи. В пределах одного индекса все ключи должны быть одной длины. Для поиска узлов применяется бираный поиск. Гибкая схема буферизации позволяет удерживать узлы в памяти до тех пор, пока памяти хватает. Если ожидается доступ к чему-нибудь упорядоченному, следует увеличить значение bufCt - это уменьшает число обращений к диску.
Также есть программа bcplus, реализующая Б-деревья для индексирования файлов. Исходники на Си.
 Вверх по странице, к оглавлению и навигации.
Вверх по странице, к оглавлению и навигации.